bridge
5 notes tagged “bridge”
-
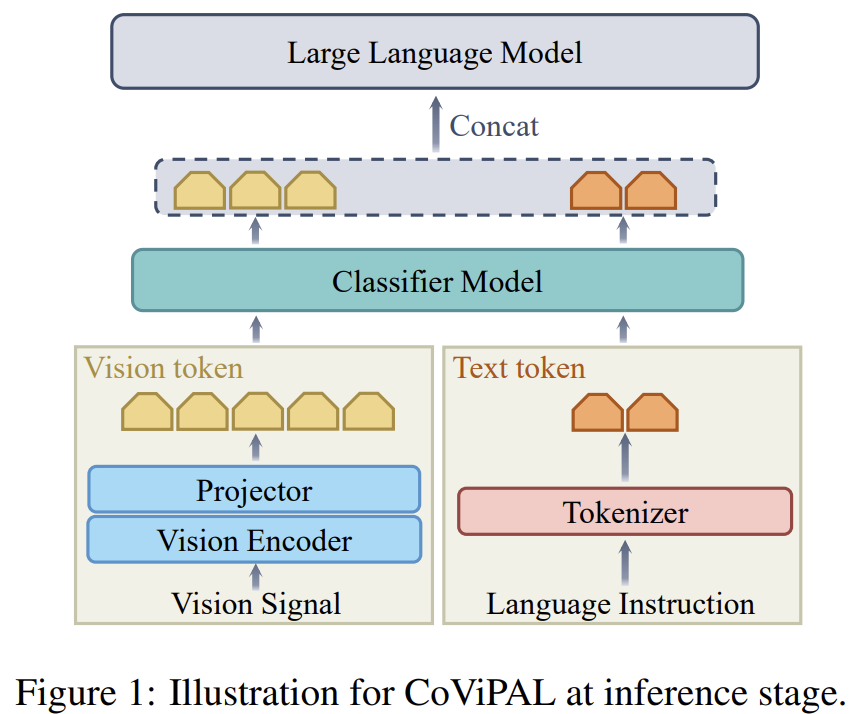
[CoViPAL] Layer-wise Contextualized Visual Token Pruning for Large Vision-Language Models
Training-free pruners struggle in shallow layers — there isn't enough context yet to tell which visual tokens are redundant. CoViPAL trains a lightweight, model-agnostic Plug-and-Play Pruning Module (PPM) that predicts and removes redundant vision tokens before the LVLM sees them, using contextual signals so pruning works even in shallow layers. Outperforms training-free pruners at equal budgets and training-based ones at comparable supervision.
-
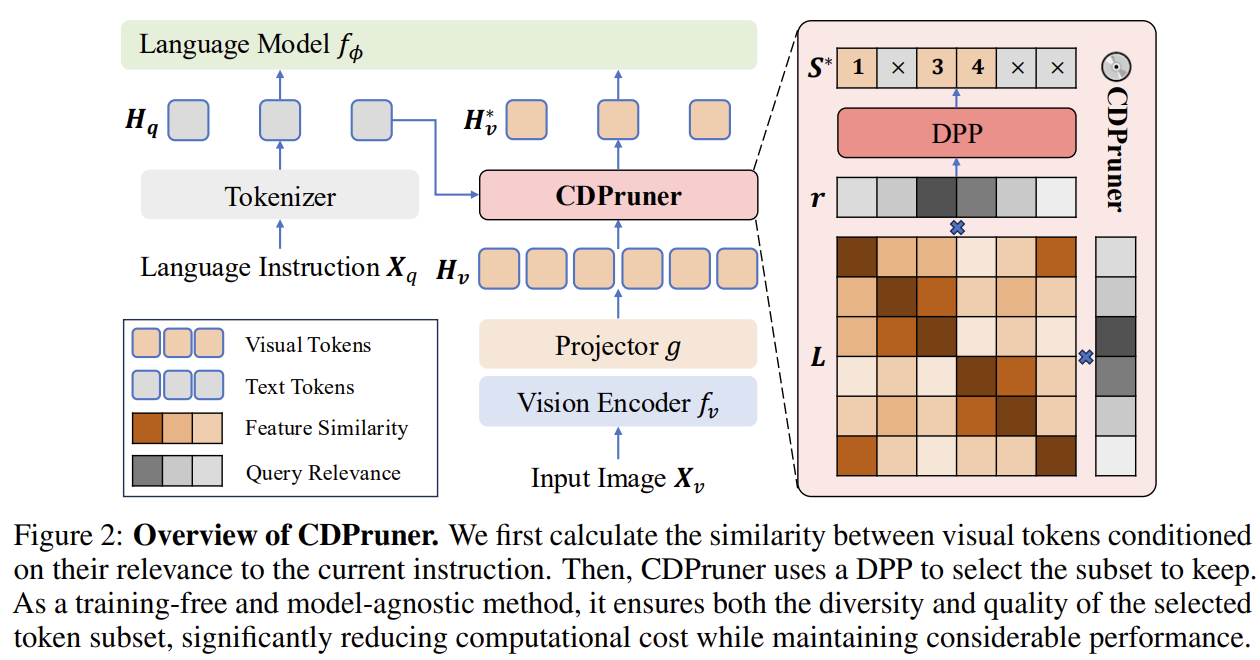
[CDPruner] Beyond Attention or Similarity: Maximizing Conditional Diversity for Token Pruning in MLLMs
Attention-based pruning keeps duplicates; similarity-based pruning ignores the instruction. CDPruner does both right: it defines visual-token similarity conditioned on the instruction, then uses a Determinantal Point Process (DPP) to pick the subset that maximizes conditional diversity — diverse AND question-relevant. Training-free, model-agnostic; on LLaVA, 95% fewer FLOPs and 78% lower latency at 94% accuracy.
-
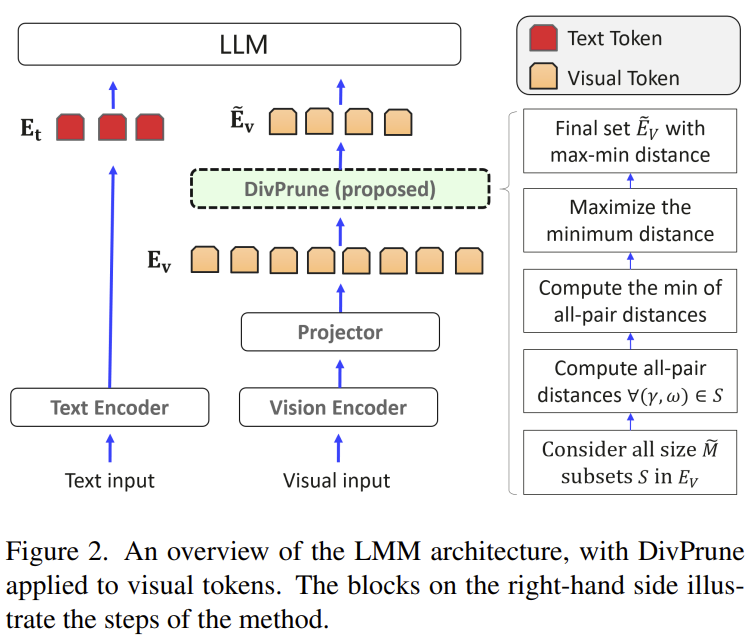
[DivPrune] Diversity-based Visual Token Pruning for Large Multimodal Models
Reframes visual token pruning as a Max-Min Diversity Problem — pick the subset of visual tokens whose mutual diversity is maximal (instead of keeping the 'most important', which are often redundant). Training-free, done once before the first LLM layer; SOTA across 16 image/video datasets with lower latency and memory.
-
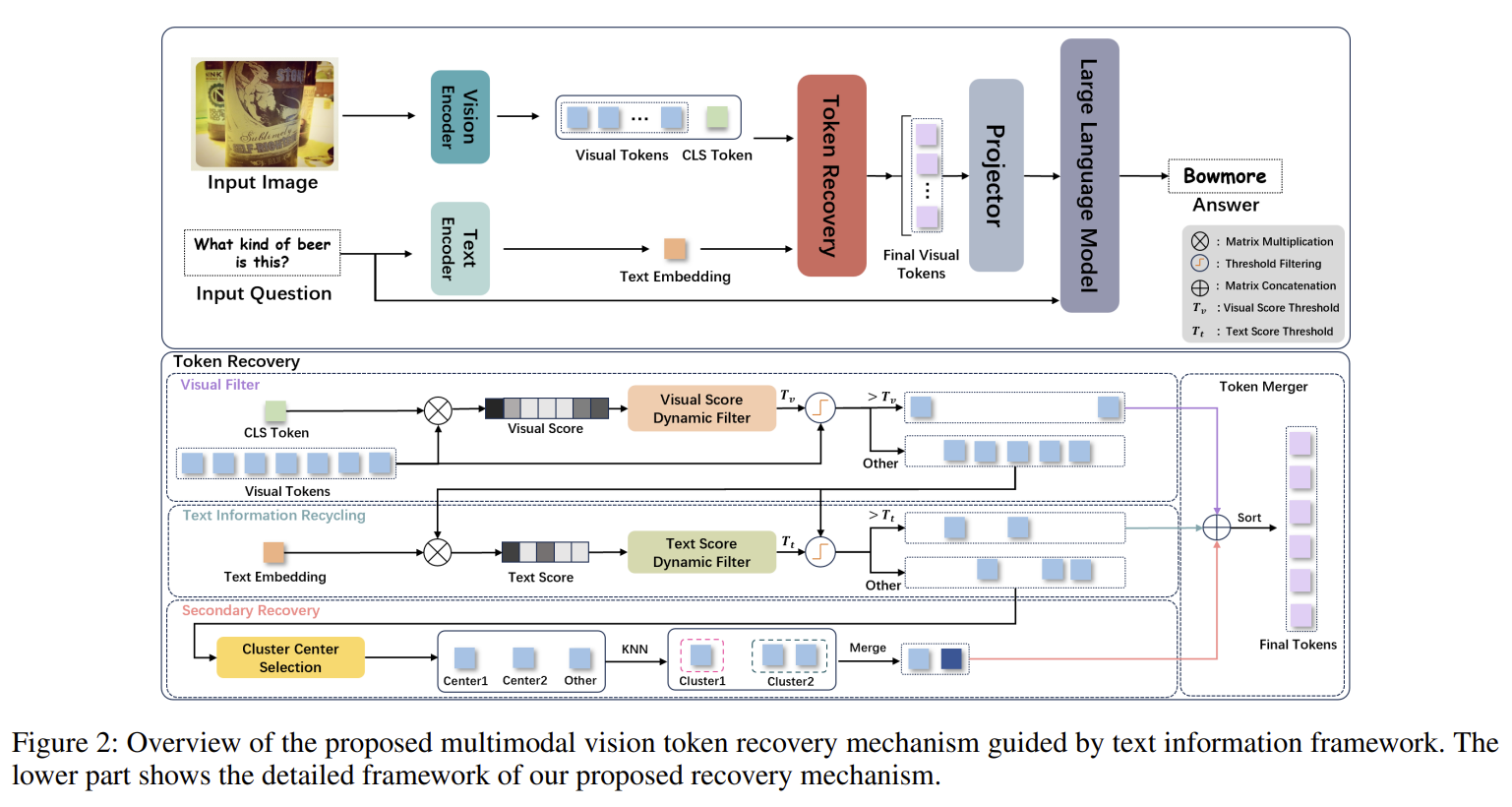
[Recoverable Compression] A Multimodal Vision Token Recovery Mechanism Guided by Text Information
Beyond pruning: after an initial CLS-based filter, it recovers visual tokens that are similar to the question text (reclaiming wrongly-dropped but answer-relevant ones) and merges the rest — training-free, compressing visual tokens to ~10% with competitive accuracy on LLaVA-1.5.
-
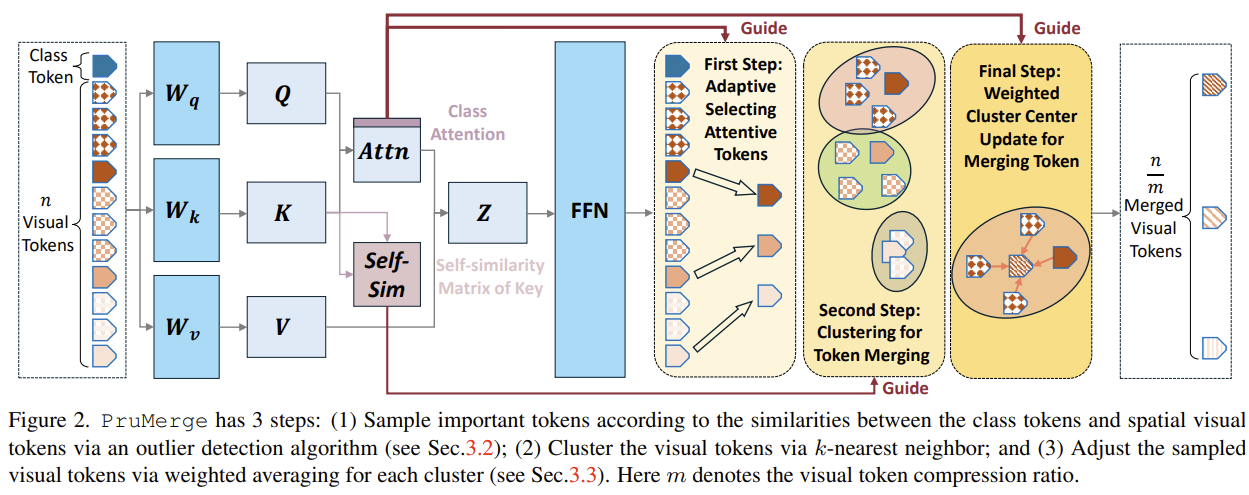
[LLaVA-PruMerge] Adaptive Token Reduction for Efficient Large Multimodal Models
The CLS-to-patch attention in the vision encoder is sparse — only a few visual tokens matter. PruMerge exploits this: it uses IQR outlier detection to adaptively keep the important tokens (more on text-rich images, fewer on simple ones), then merges the rest into them via k-NN weighted averaging. Training-free; ~5.5% of tokens (~32 of 576) keeps LLaVA-1.5 performance.