encoder-llm
1 note tagged “encoder-llm”
-
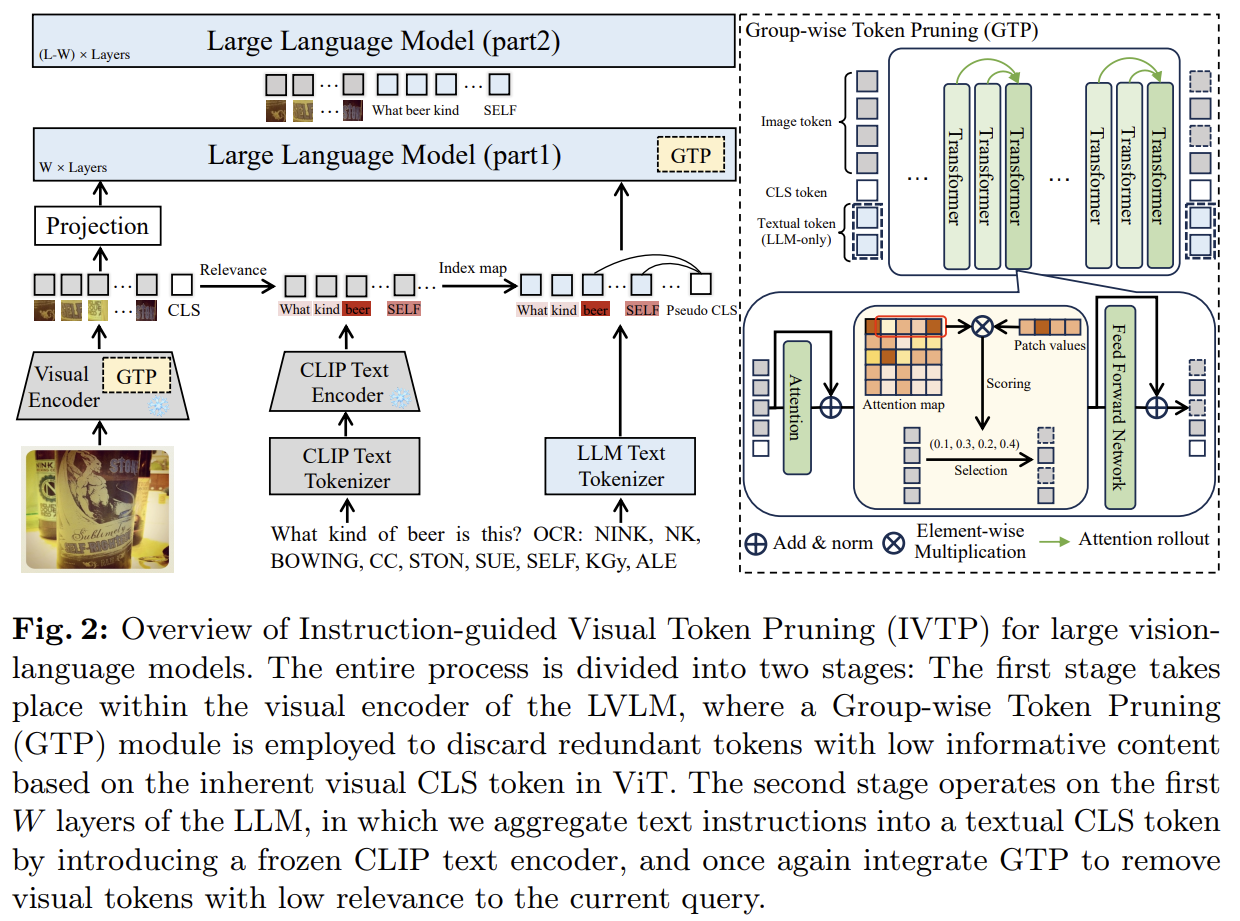
[IVTP] Instruction-guided Visual Token Pruning for Large Vision-Language Models
Two-stage visual token pruning for LVLMs — a Group-wise Token Pruning (attention rollout) inside the frozen ViT, then an instruction-guided filter inside the LLM using a pseudo CLS token. Training-free: cuts 88.9% of visual tokens (FLOPs −46%) with only ~1% drop on LLaVA-1.5.