encoder-side
6 notes tagged “encoder-side”
-
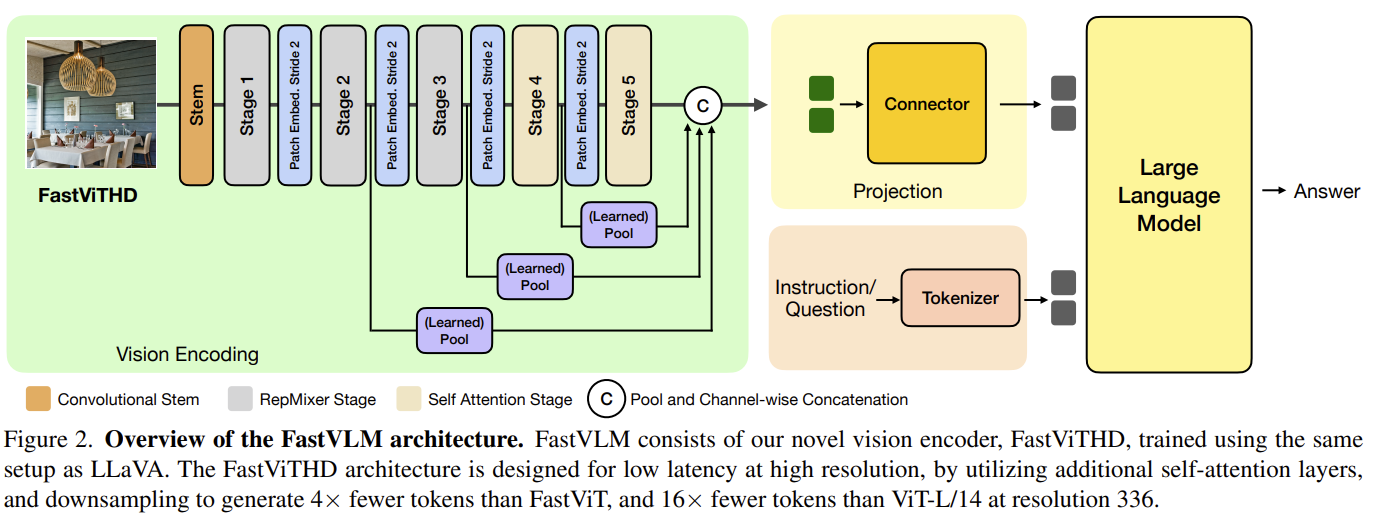
[FastVLM] Efficient Vision Encoding for Vision Language Models
Instead of pruning tokens after the encoder, FastVLM fixes the encoder itself. FastViTHD — a hybrid (conv + transformer) vision encoder — outputs far fewer tokens and encodes high-resolution images much faster, so the right token-count/resolution balance comes simply from scaling the input image, no token pruning needed. 3.2× faster time-to-first-token at similar accuracy.
-
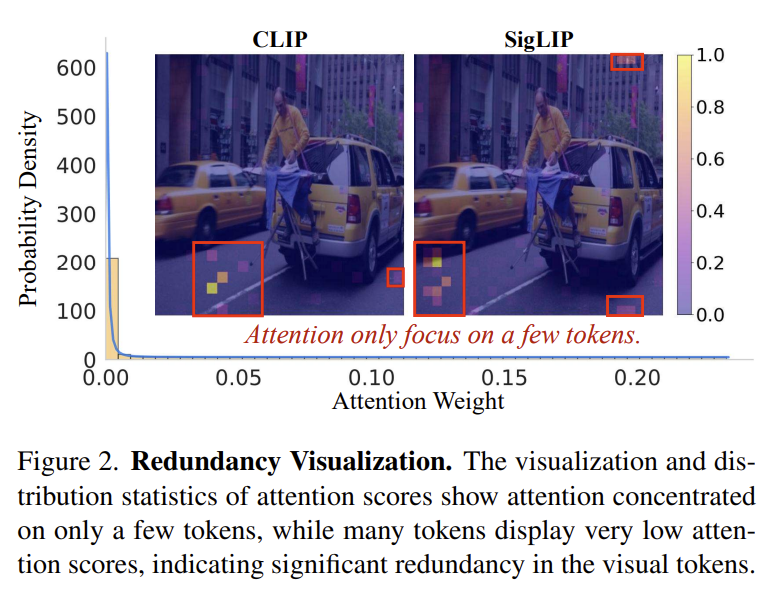
[VisionZip] Longer is Better but Not Necessary in Vision Language Models
Vision encoders (CLIP/SigLIP) emit highly redundant visual tokens — VisionZip keeps only a few dominant tokens (high attention) plus merged contextual tokens, text-agnostic and training-free. 8× faster prefilling at 95% performance; shines in multi-turn dialogue where text-guided pruners fail.
-
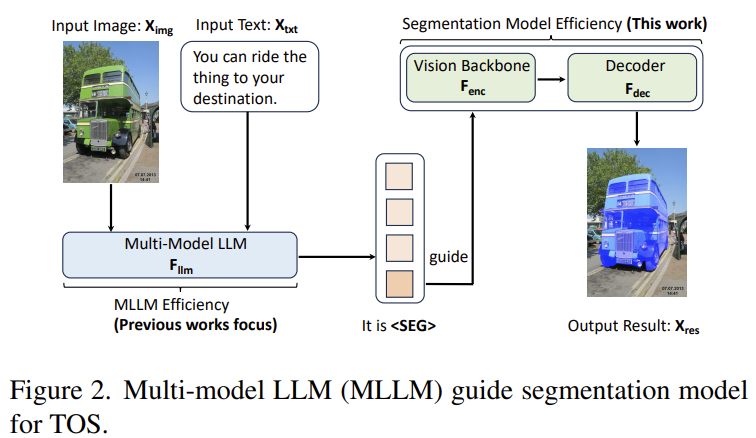
[VLTP] Vision-Language Guided Token Pruning for Task-Oriented Segmentation
Accelerates ViT-based segmentation by pruning image tokens that aren't relevant to the task — a prune decoder uses MLLM guidance to score each token's task-relevance, keeping only relevant tokens in deeper ViT layers. ~25% ViT FLOPs cut with no drop (40% with 1%).
-
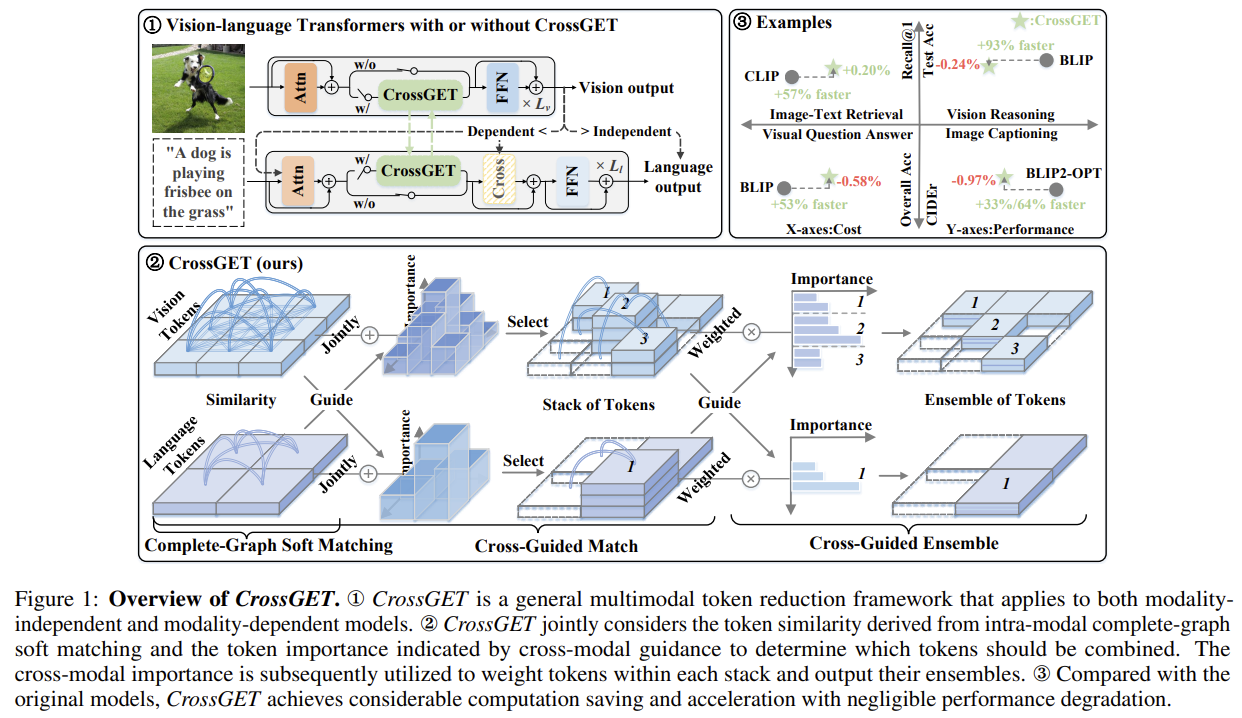
[CrossGET] Cross-Guided Ensemble of Tokens for Accelerating Vision-Language Transformers
Reduces tokens inside vision-language Transformers by ensembling (merging) them, guided by cross-modal importance — works on both modality-independent (CLIP) and modality-dependent (BLIP-2) models via learnable cross tokens and a parallelizable complete-graph soft matching.
-
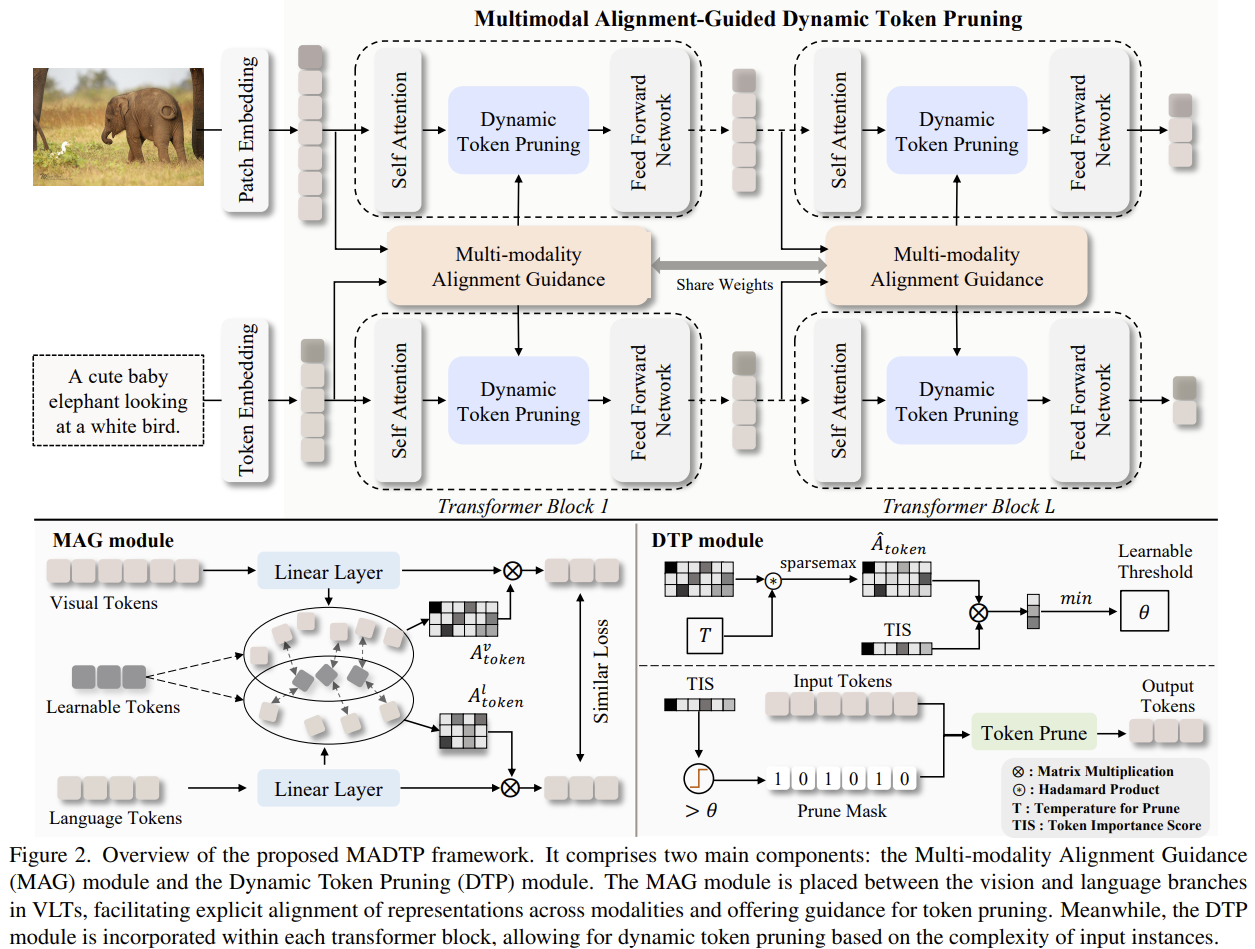
[MADTP] Multimodal Alignment-Guided Dynamic Token Pruning for Accelerating Vision-Language Transformer
Prunes tokens inside vision-language Transformers, but guided by cross-modal alignment (MAG) so a token isn't cut in one branch while still vital in the other — plus per-layer, per-instance dynamic ratios (DTP). 80% fewer GFLOPs on BLIP/NLVR2 with <4% drop.
-
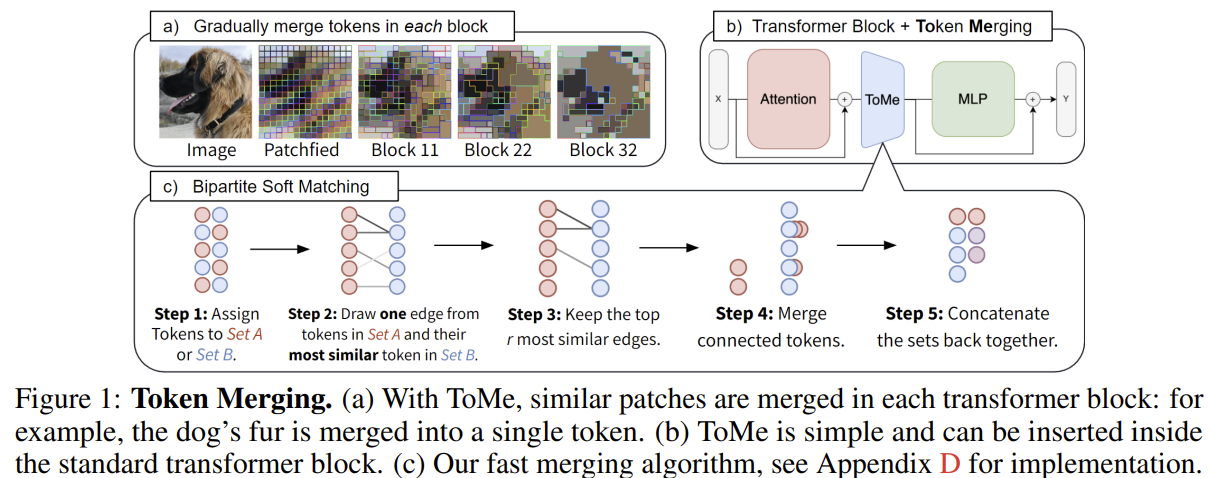
[ToMe] Token Merging: Your ViT But Faster
Combine similar tokens (not prune) via bipartite soft matching, fast as pruning, works even without training.