llm-side
6 notes tagged “llm-side”
-
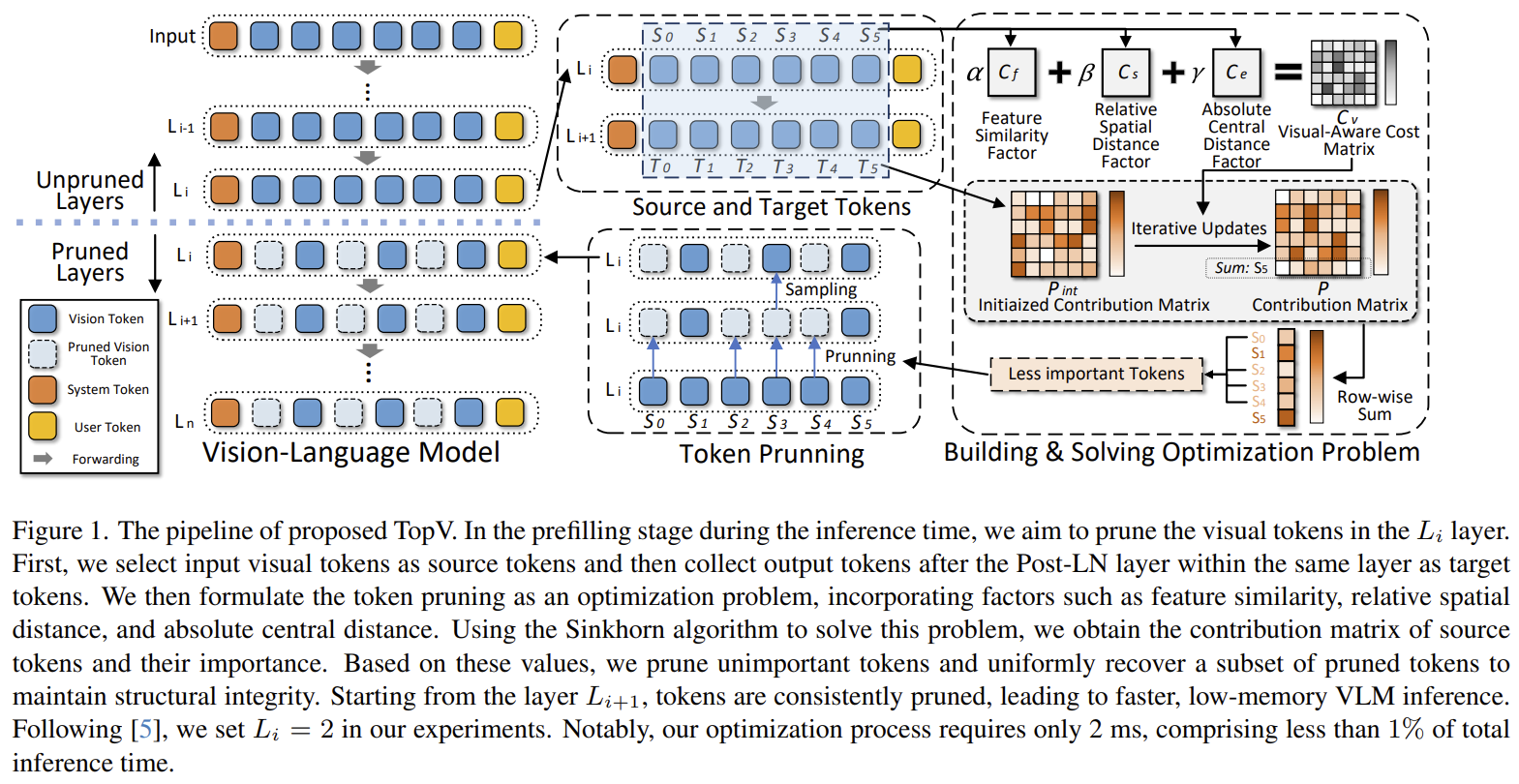
[TopV] Compatible Token Pruning with Inference Time Optimization for Fast and Low-Memory VLM
Most LLM-side pruners rank visual tokens by attention score — which is a greedy heuristic AND breaks FlashAttention and the KV cache. TopV instead formulates pruning as an optimization problem with a vision-aware cost (feature similarity + spatial + central distance), solves it with Sinkhorn, and prunes once at prefilling — staying compatible with FlashAttention and KV cache. Training-free.
-
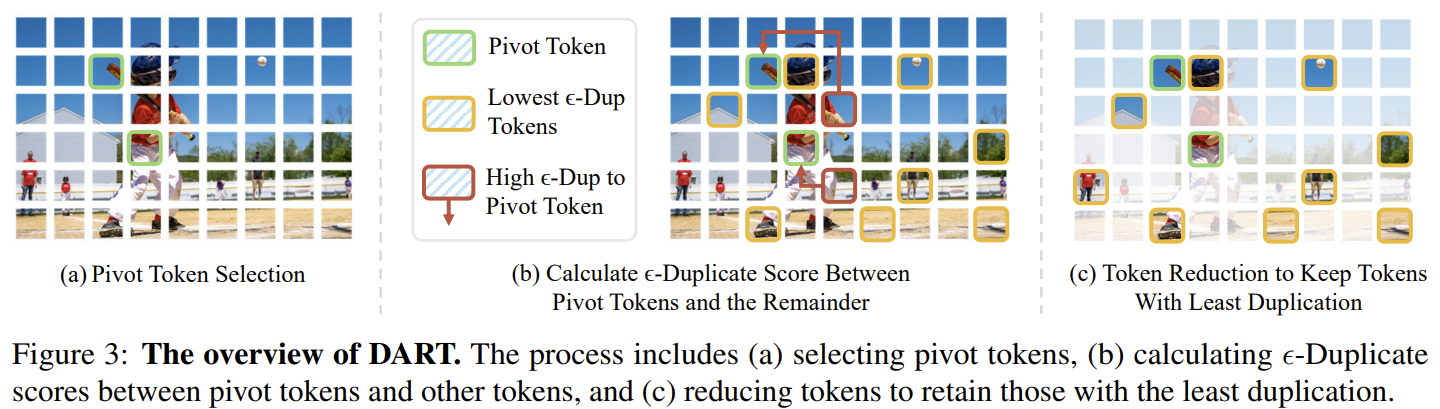
[DART] Stop Looking for "Important Tokens": Duplication Matters More
A contrarian take: token importance is a bad pruning criterion — importance-based methods often do worse than random pruning and break efficient attention. DART (Duplication-Aware Reduction of Tokens) instead picks a tiny set of pivot tokens and keeps the tokens least duplicated with them. Training-free, Flash-Attention-friendly; prunes 88.9% of vision tokens with comparable accuracy and 2.99× faster prefilling.
-
[ATP-LLaVA] Adaptive Token Pruning for Large Vision Language Models
Fixed pruning ratios are suboptimal — the right amount to cut varies by LLM layer and by instance (image-prompt). ATP-LLaVA learns an Adaptive Token Pruning module that sets an instance- and layer-specific ratio, plus a Spatial Augmented Pruning strategy. Cuts ~75% of tokens with only 1.9% drop.
-
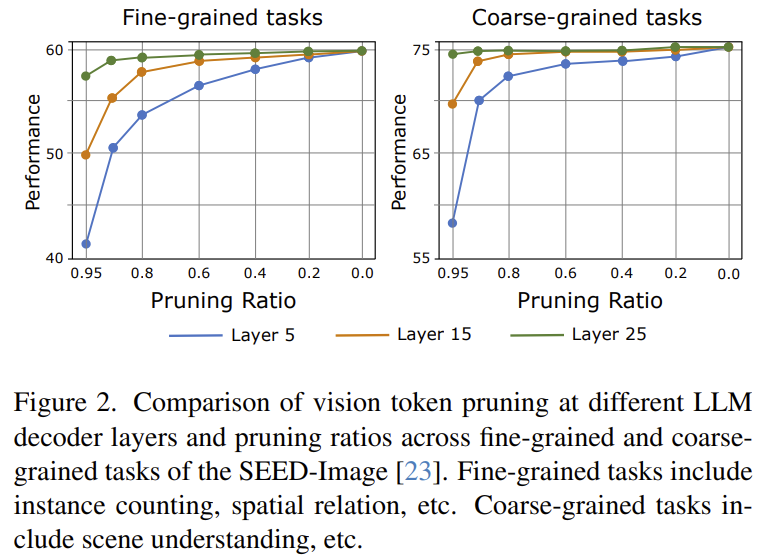
[PyramidDrop] Accelerating Large Vision-Language Models via Pyramid Visual Redundancy Reduction
Empirically shows visual tokens are all needed in shallow LLM layers but grow redundant in deeper ones — so it splits the LLM into stages and drops a fixed ratio of image tokens at the end of each stage (pyramid). Accelerates both training (−40%) and inference (−55% FLOPs).
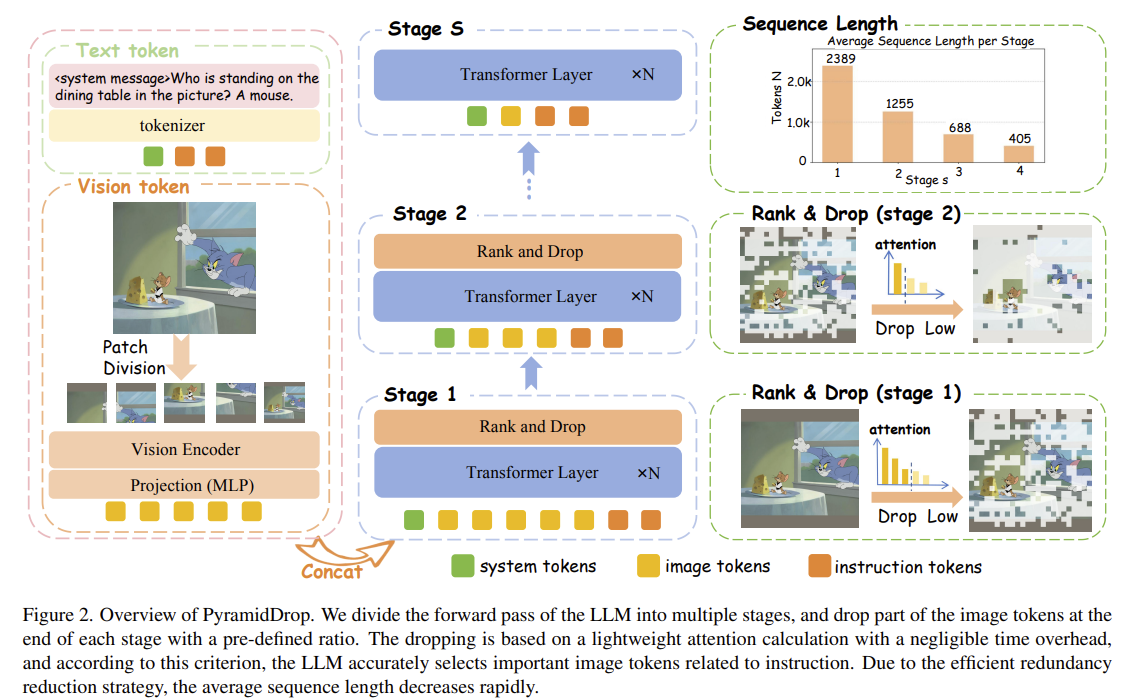
-
[SparseVLM] Visual Token Sparsification for Efficient Vision-Language Model Inference
Training-free, text-guided visual token sparsification inside the LLM — relevant text tokens act as 'raters' to score visual tokens via self-attention, a rank-based rule sets the per-layer ratio, and pruned tokens are recycled by clustering. 4.5× compression keeping 97% on LLaVA; beats FastV.
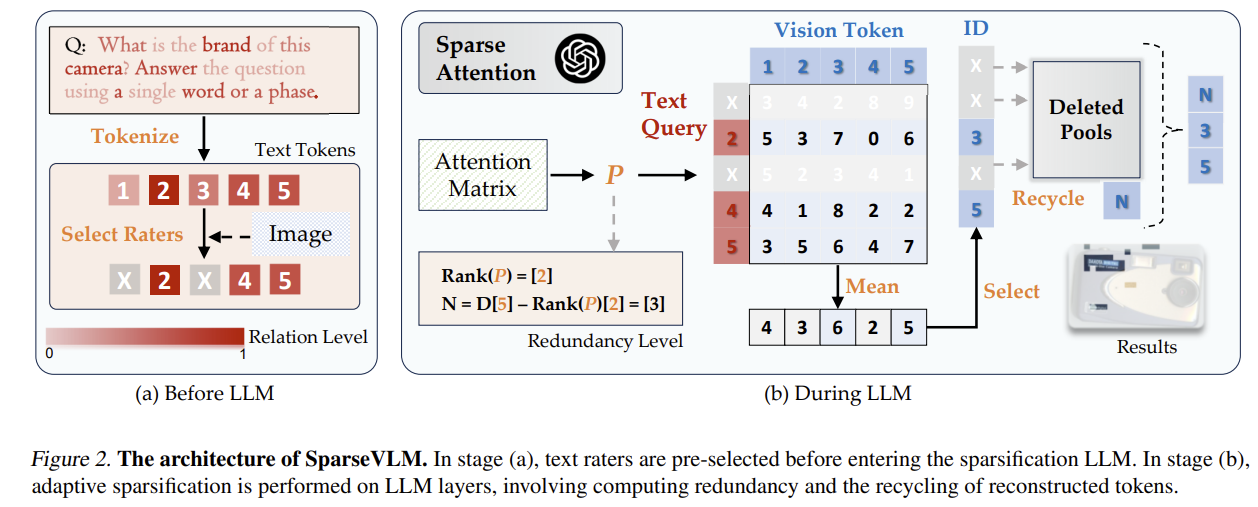
-
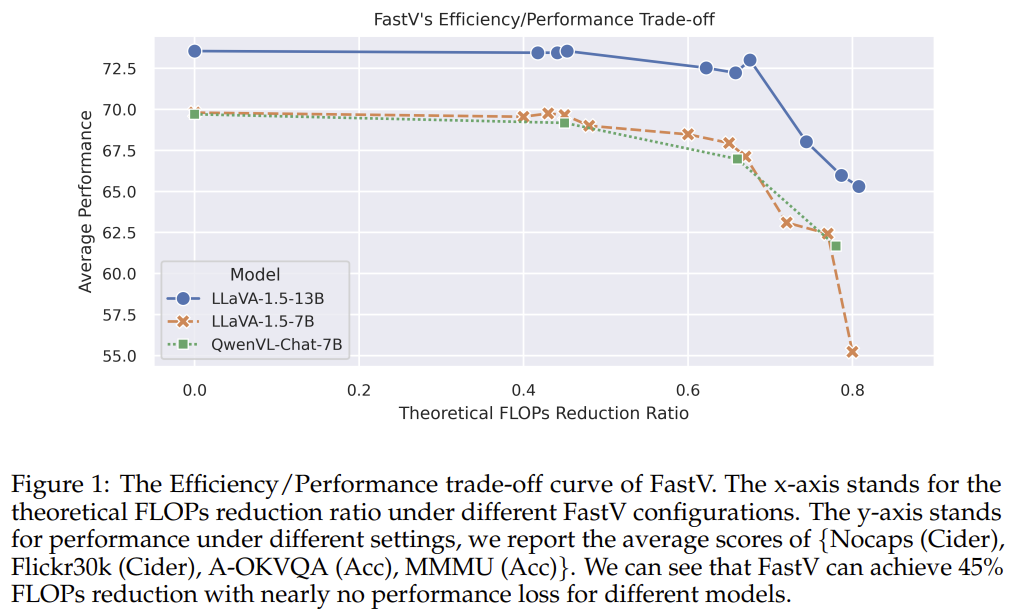
[FastV] An Image is Worth 1/2 Tokens After Layer 2
Observes that in deep LLM layers of LVLMs, visual tokens receive almost no attention — so after an early layer (e.g., layer 2) it prunes low-attention visual tokens. Training-free plug-and-play: 45% FLOPs cut on LLaVA-1.5-13B with no performance loss.