modality-encoder
1 note tagged “modality-encoder”
-
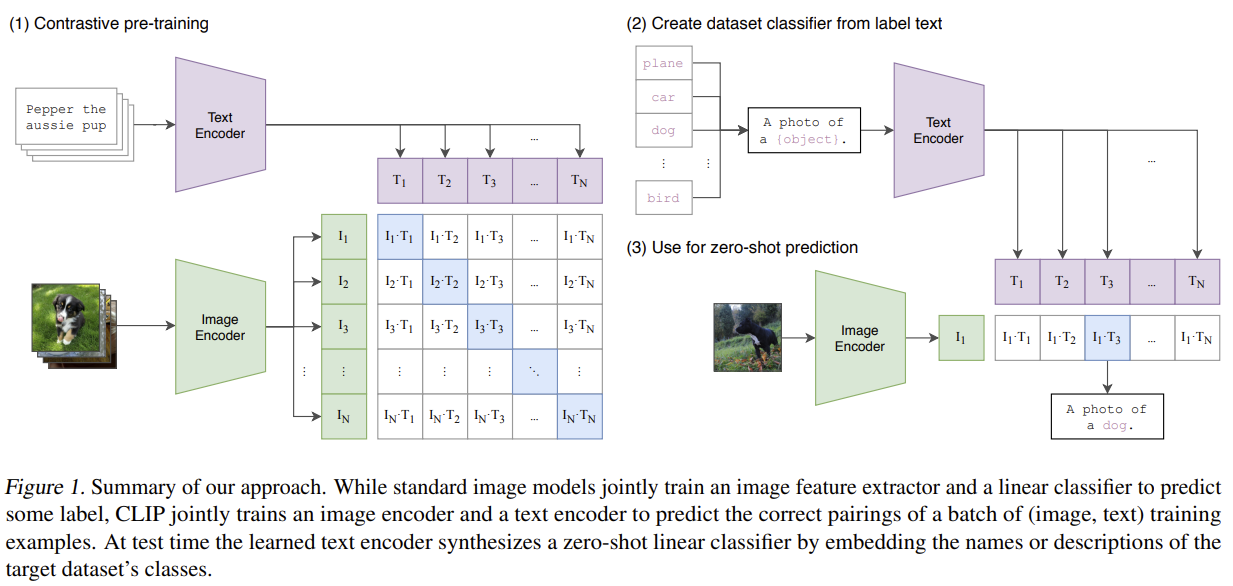
[CLIP] Learning Transferable Visual Models From Natural Language Supervision
Trains an image encoder and a text encoder to match images with their captions (contrastive) on 400M web pairs — enabling open-vocabulary zero-shot transfer, and becoming the vision encoder most VLMs freeze and reuse.