Token Reduction in ViTs
18 notes in this category
-
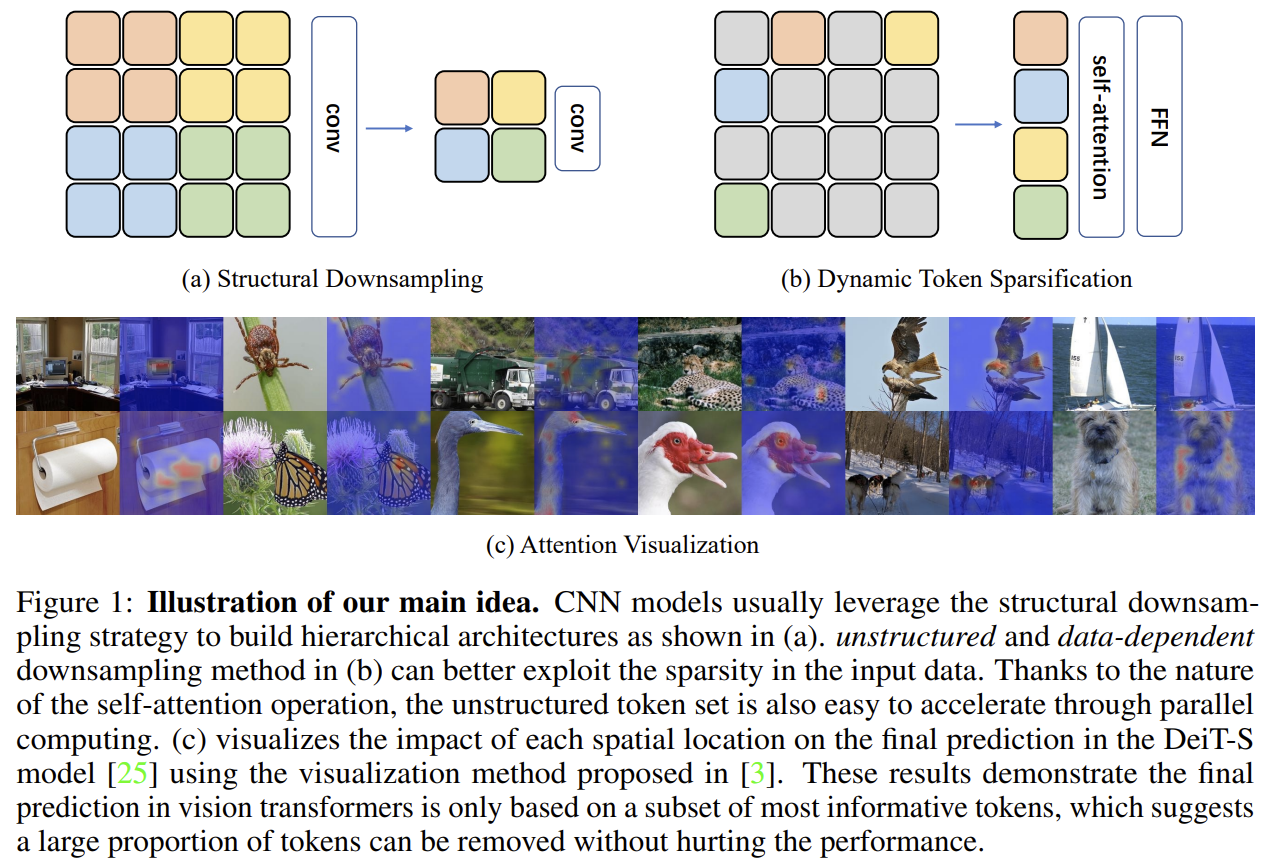
Token Reduction in ViTs — Overview
ViT token efficiency — Pruning · Merging · Pooling · Hybrid, with 17 key papers at a glance.
-
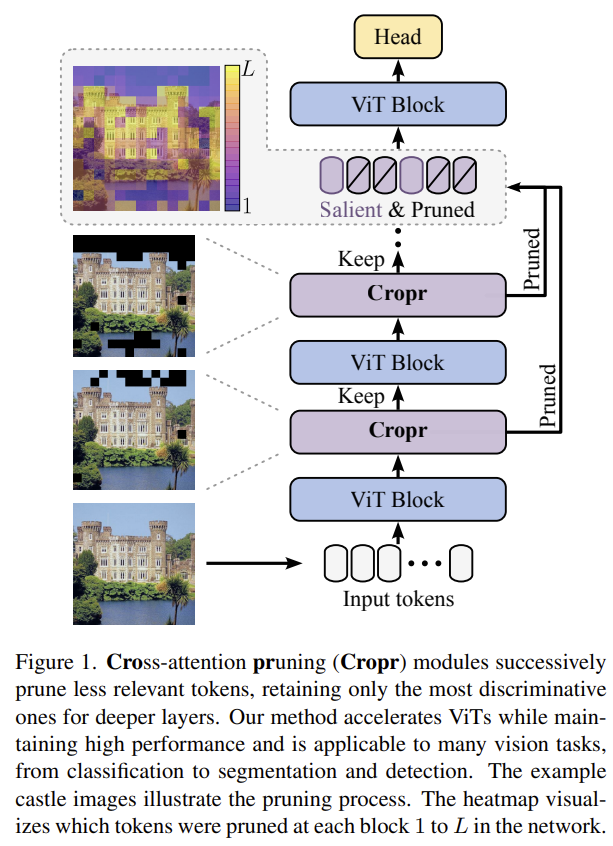
[Token Cropr] Token Cropr: Faster ViTs for Quite a Few Tasks
Prunes tokens by task relevance using auxiliary cross-attention heads that are thrown away after training, plus Last Layer Fusion to revive pruned tokens for dense tasks.
-
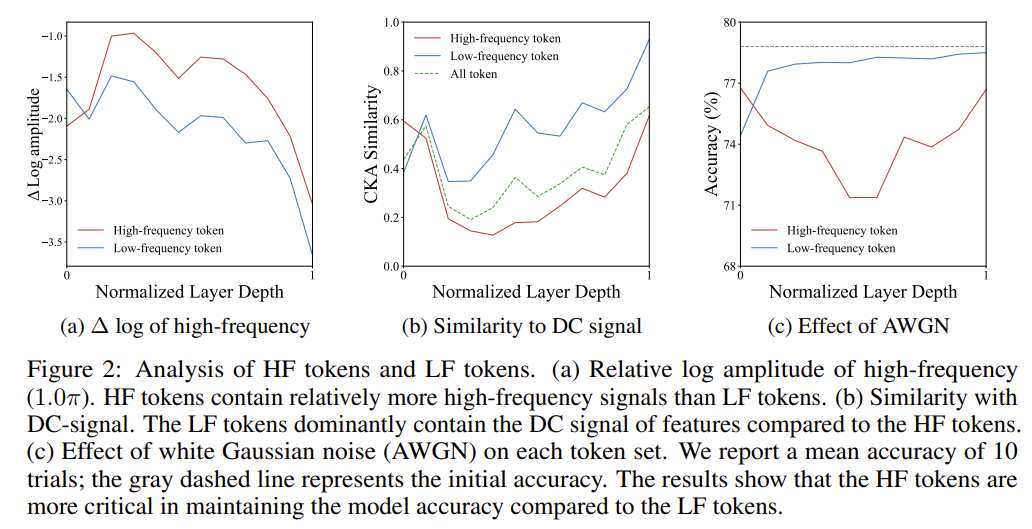
[Frequency-Aware TR] Frequency-Aware Token Reduction for Efficient Vision Transformer
Reads token reduction through a frequency lens: keeps high-frequency tokens (which fight rank collapse) and squeezes the low-frequency rest into a compact DC token.
-
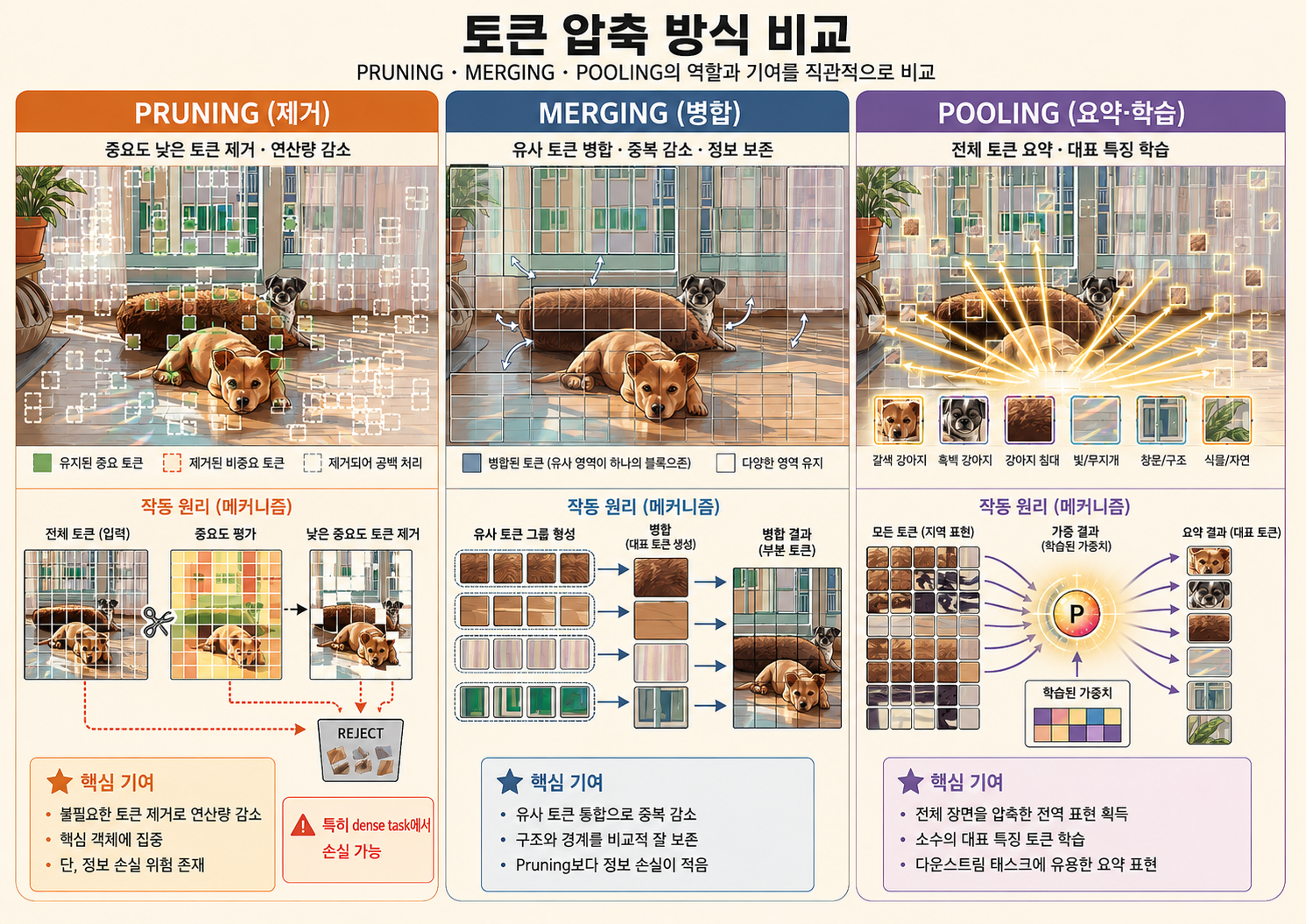
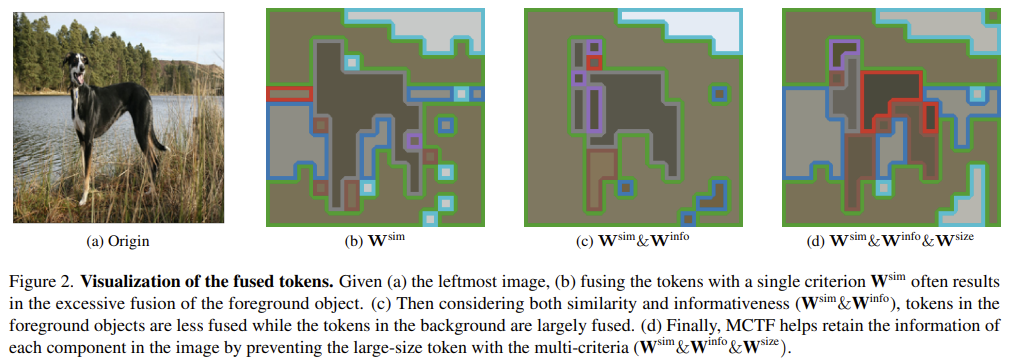
[MCTF] Multi-criteria Token Fusion with One-step-ahead Attention for Efficient Vision Transformers
Fuses tokens by a product of three criteria — similarity, informativeness, size — with one-step-ahead attention and bidirectional bipartite matching, beating the base model while cutting FLOPs.
-
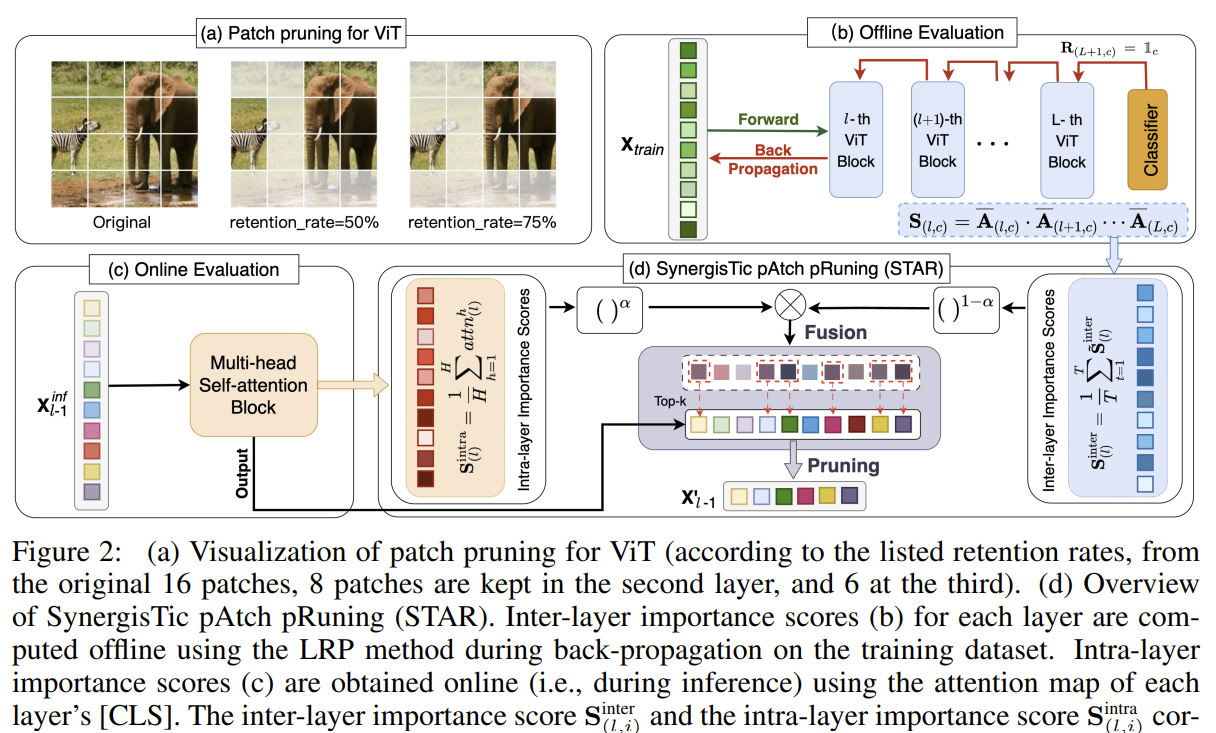
[STAR] Synergistic Patch Pruning for Vision Transformer: Unifying Intra- & Inter-Layer Patch Importance
Fuses online intra-layer [CLS] attention with offline inter-layer LRP importance, and auto-tunes per-layer retention rates from patch similarity.
-
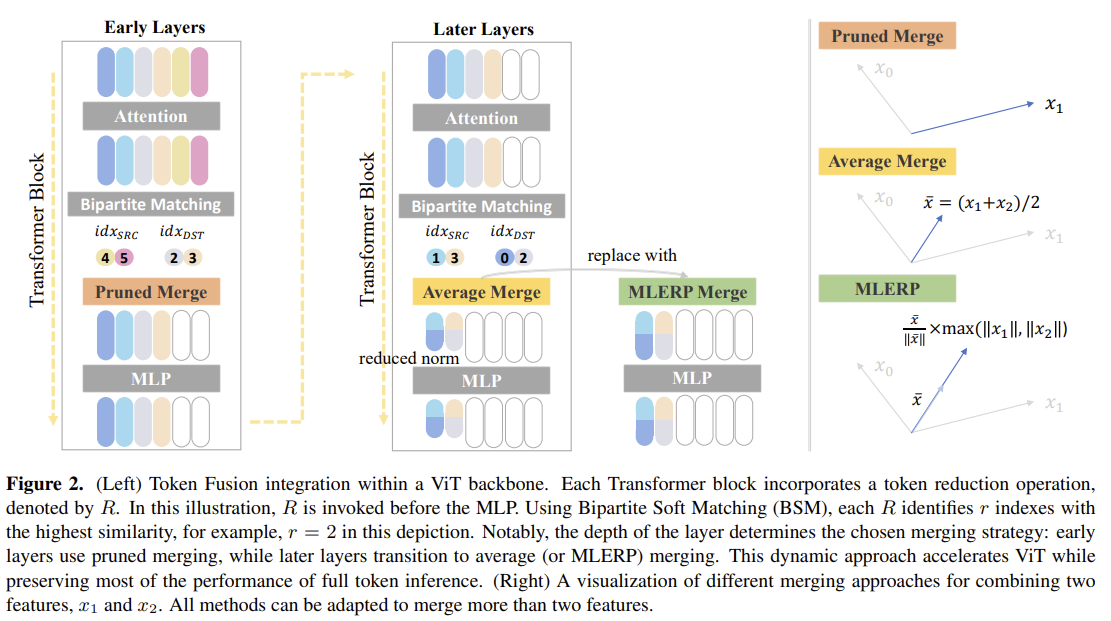
[Token Fusion / ToFu] Bridging the Gap between Token Pruning and Token Merging
Switches between pruning (early layers) and merging (later layers) by each layer's functional linearity, with a norm-preserving MLERP merge.
-
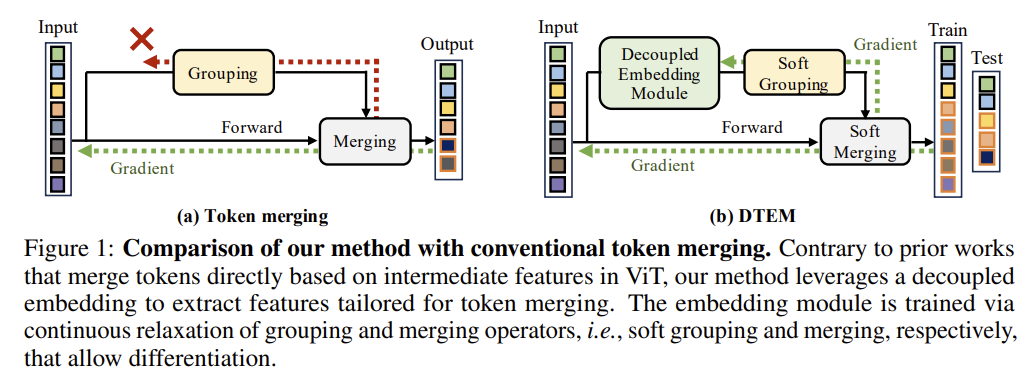
[DTEM] Learning to Merge Tokens via Decoupled Embedding for Efficient Vision Transformers
Learns a lightweight embedding dedicated to merging — decoupled from the ViT forward pass — via a continuously relaxed (differentiable) token merging.
-
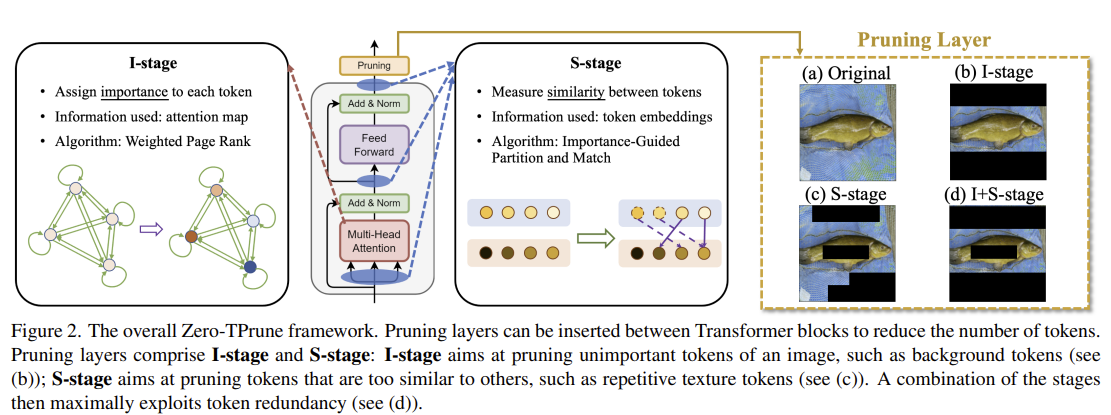
[Zero-TPrune] Zero-Shot Token Pruning through Leveraging of the Attention Graph in Pre-Trained Transformers
Treats the attention matrix as a directed graph and ranks tokens with a Weighted PageRank — pruning without any fine-tuning.
-
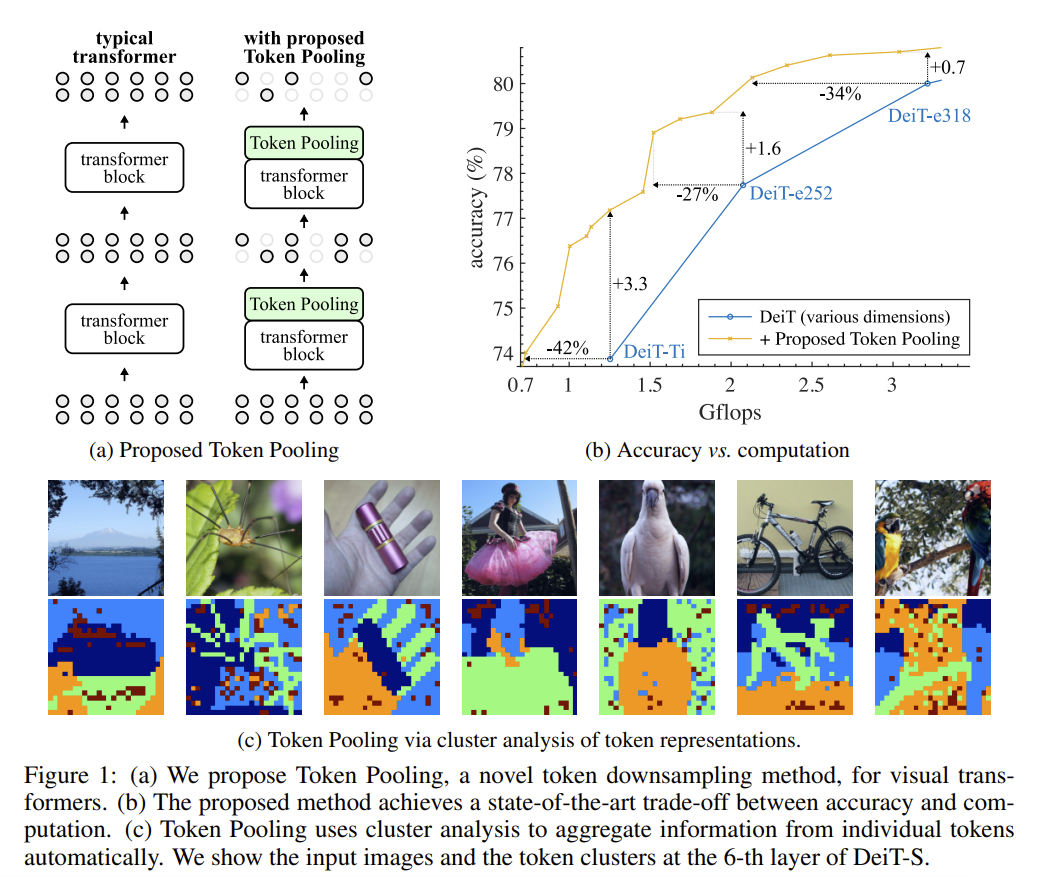
[Token Pooling] Token Pooling in Vision Transformers
Reframes token downsampling as minimizing reconstruction error, and solves it with simple, parameter-free clustering (K-Means / K-Medoids).
-
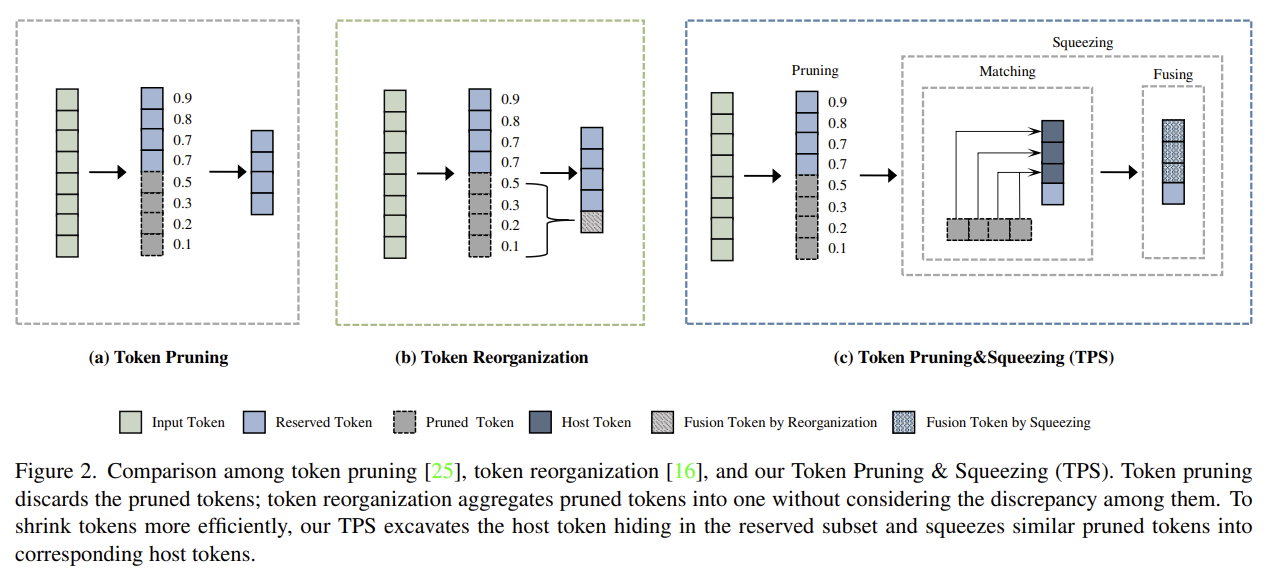
[TPS] Joint Token Pruning & Squeezing Towards More Aggressive Compression of Vision Transformers
Instead of throwing pruned tokens away, squeezes their information into the surviving 'host' tokens — parameter-free matching + similarity-based fusing.
-
[DiffRate] Differentiable Compression Rate for Efficient Vision Transformers
Makes the per-layer compression rate differentiable, and prunes + merges in one unified framework.

-
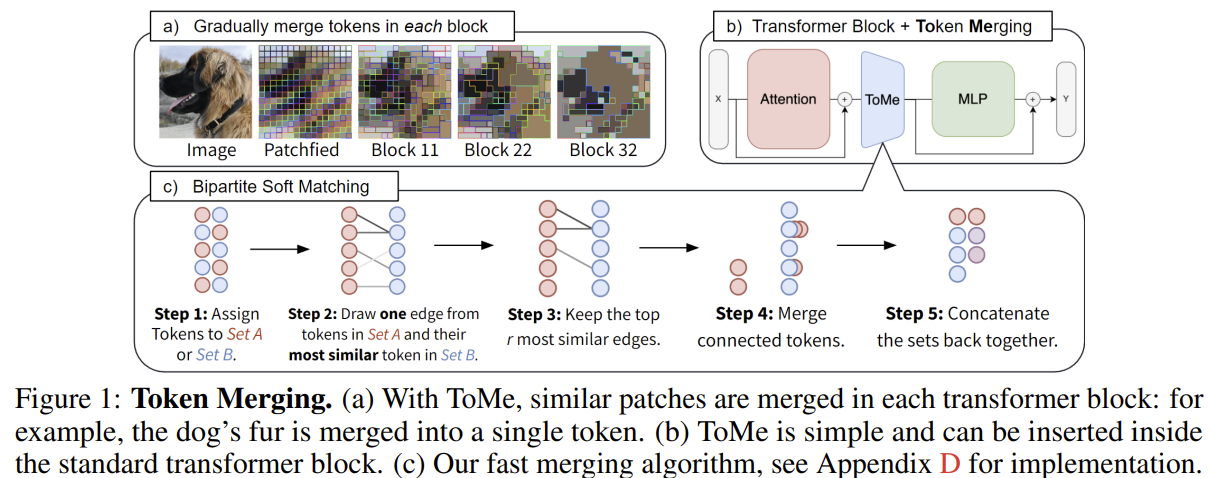
[ToMe] Token Merging: Your ViT But Faster
Combine similar tokens (not prune) via bipartite soft matching, fast as pruning, works even without training.
-
[AS-ViT] Adaptive Sparse ViT: Learnable Adaptive Token Pruning by Fully Exploiting Self-Attention
Learnable thresholds replace fixed keep-ratios, scoring tokens for free from MHSA's own intermediate results.

-
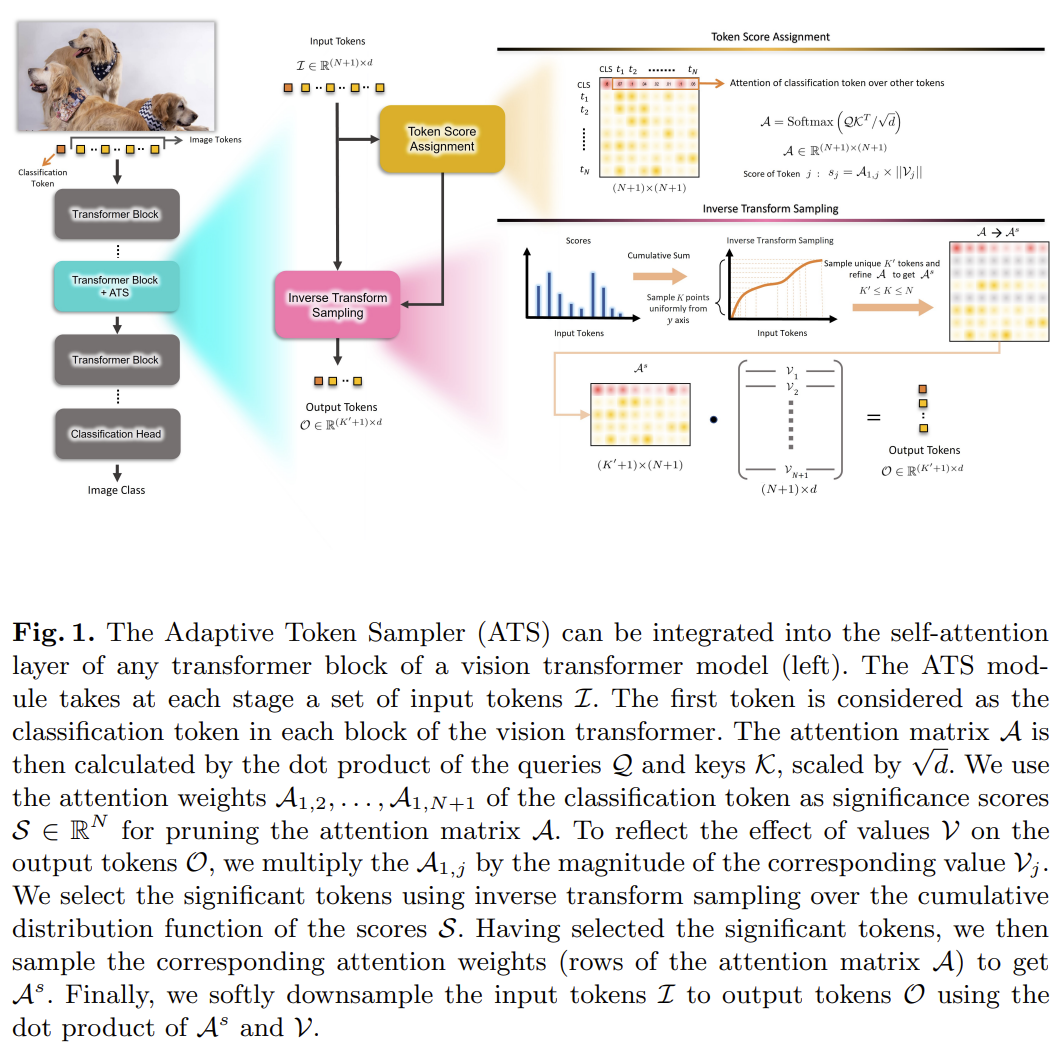
[ATS] Adaptive Token Sampling for Efficient Vision Transformers
Parameter-free, picks a variable number of tokens per image by sampling the attention CDF.
-
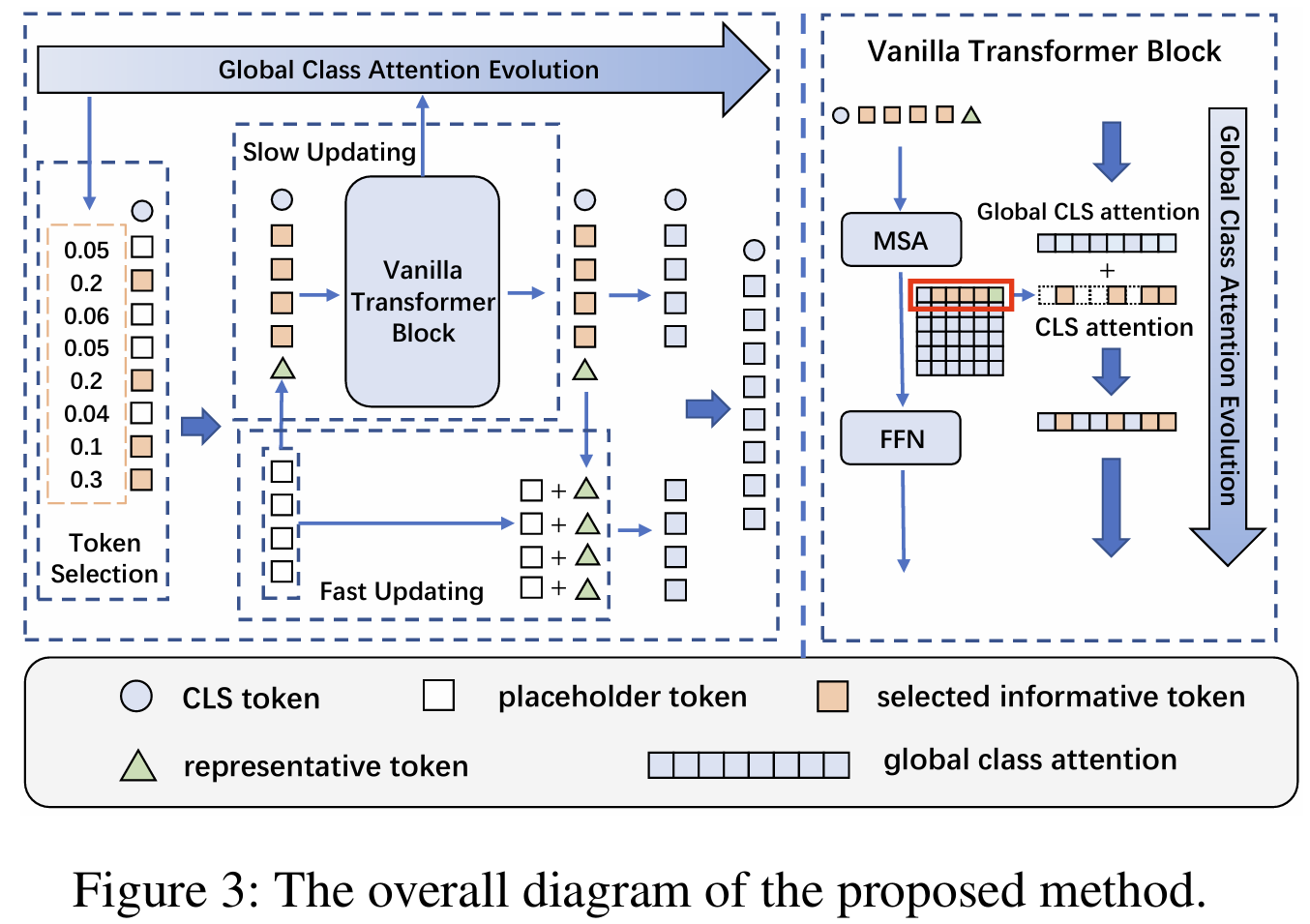
[Evo-ViT] Slow-Fast Token Evolution for Dynamic Vision Transformer
Keep all tokens but update informative vs placeholder tokens on different paths.
-
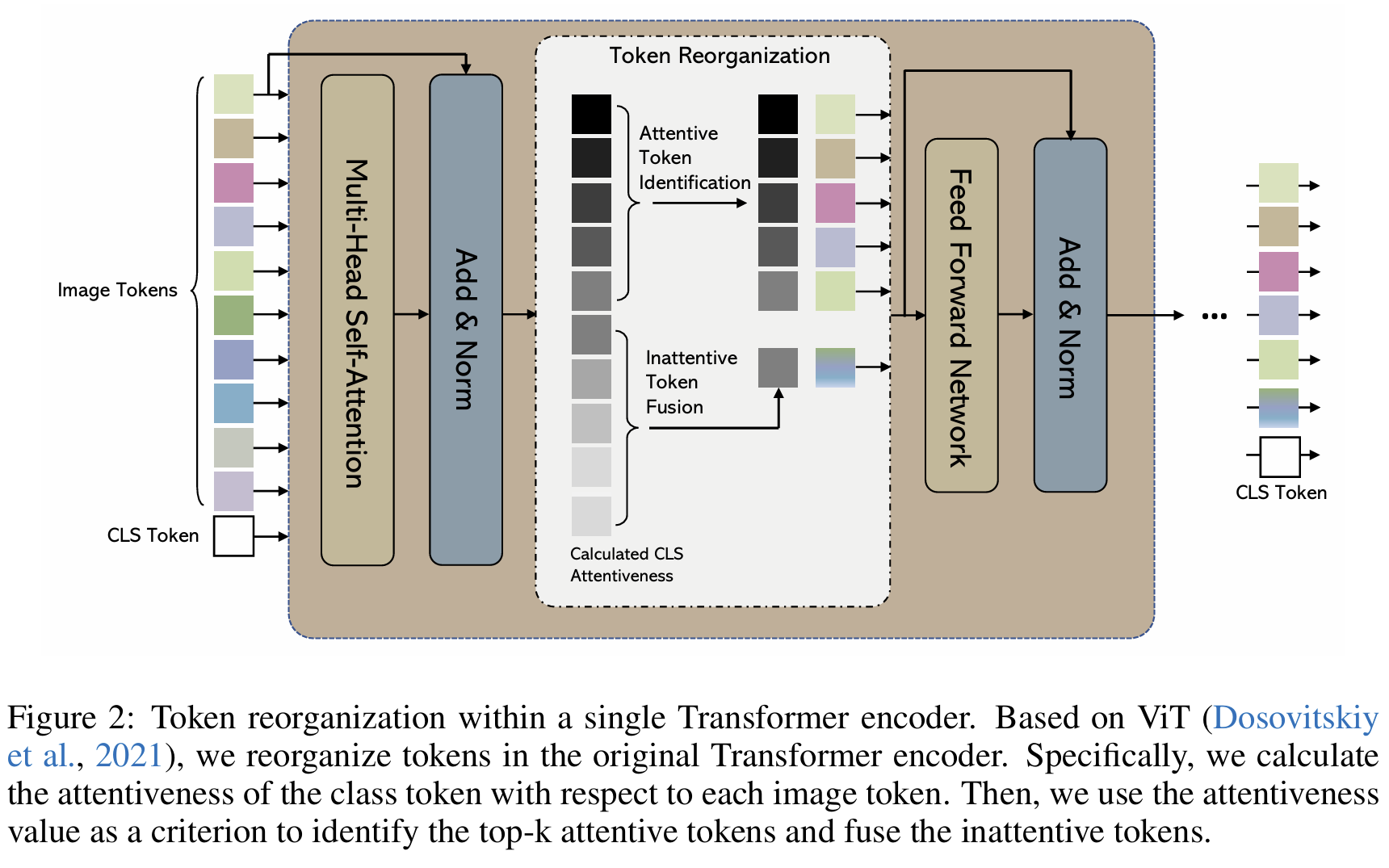
[EViT] Not All Patches Are What You Need: Expediting ViTs via Token Reorganizations
Keep top-k attentive tokens by CLS attention, fuse the rest into one.
-
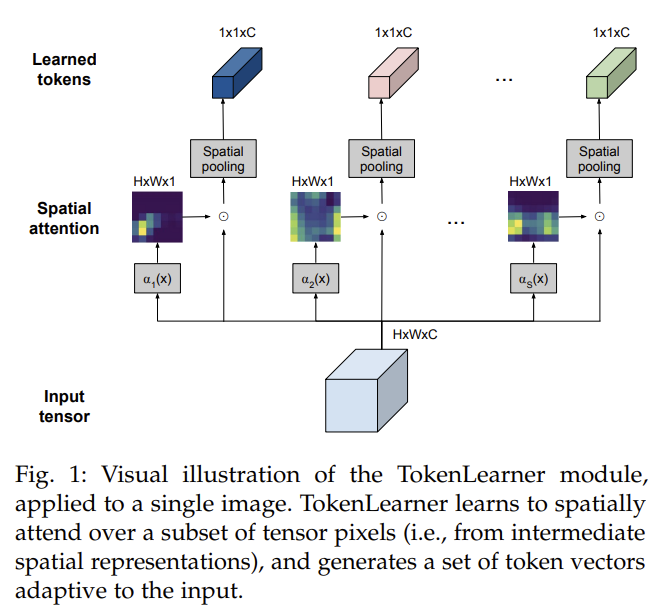
[TokenLearner] What Can 8 Learned Tokens Do for Images and Videos?
Learns a handful of adaptive tokens instead of a dense uniform grid.
-
[DynamicViT] Efficient Vision Transformers with Dynamic Token Sparsification
Dynamically drops redundant tokens per input to speed up ViTs.