input-projector
1 note tagged “input-projector”
-
[P-Former] Bootstrapping Vision-Language Learning with Decoupled Language Pre-training
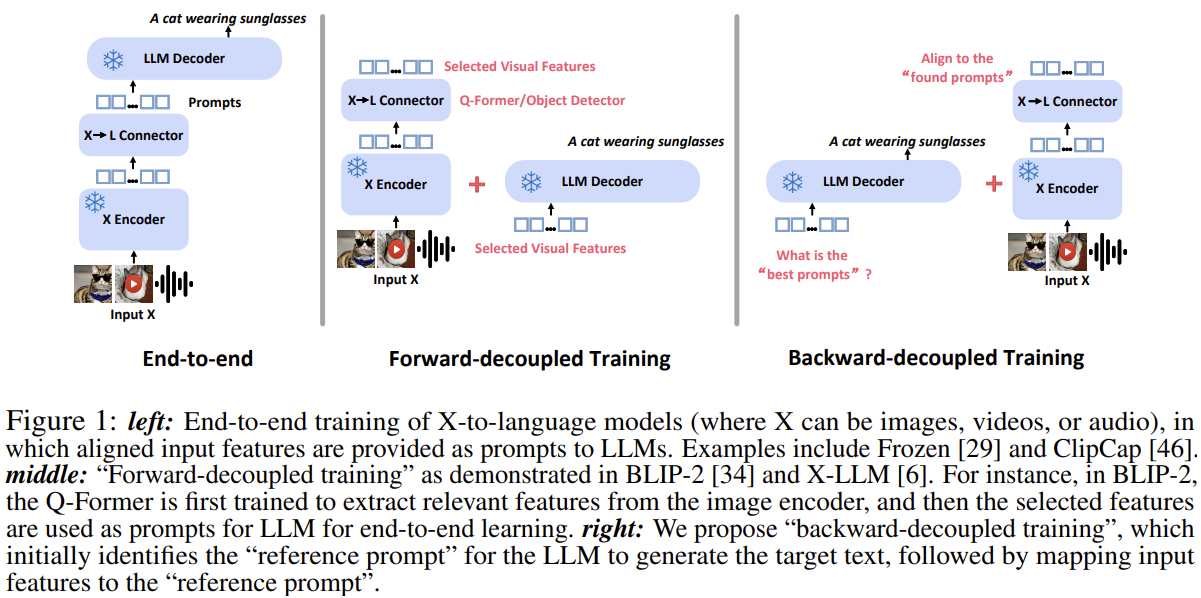
Flips the usual connector training: instead of asking 'which visual features make a good prompt', P-Former first learns — from text only — the ideal 'reference prompt' a frozen LLM needs, then aligns visual features to it. A training-only module that boosts BLIP-2's data efficiency.