vlm
11 notes tagged “vlm”
-
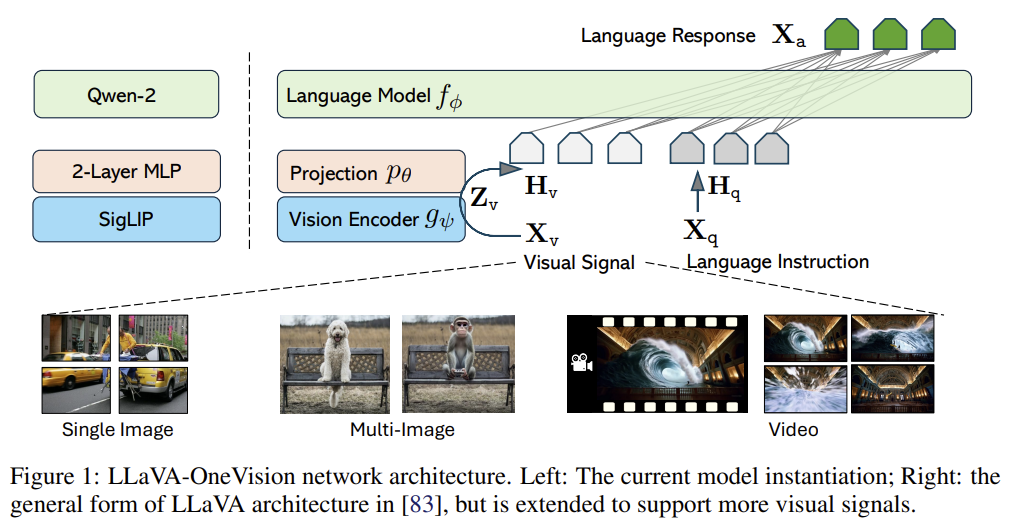
[LLaVA-OneVision] Easy Visual Task Transfer
The first single open LMM strong across single-image, multi-image, and video — with cross-scenario task transfer (video understanding emerges from image training) via a balanced AnyRes token budget.
-
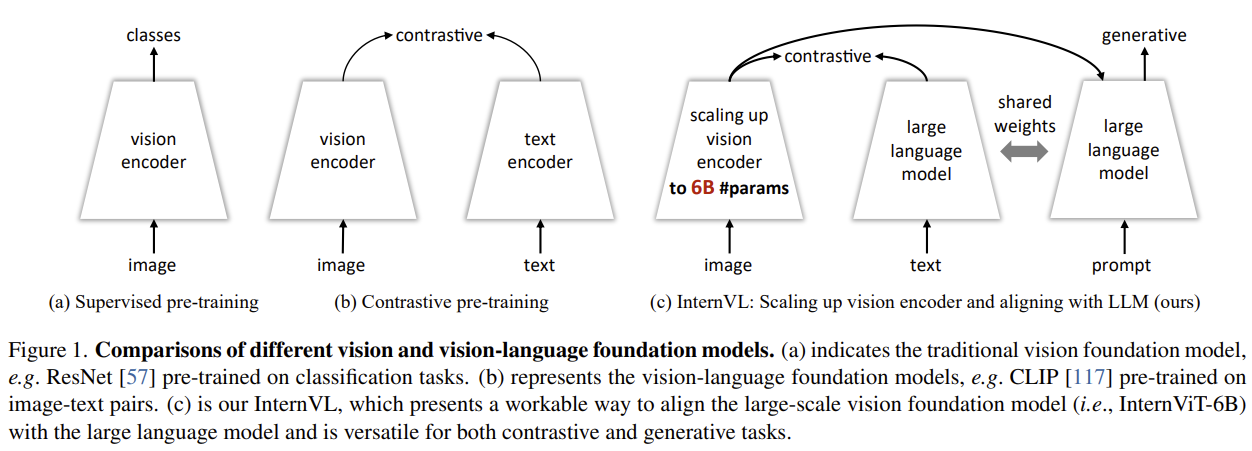
[InternVL] Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Argues the vision encoder is too small next to the LLM, so it scales the encoder to 6B (InternViT-6B) and bridges it with an 8B language middleware (QLLaMA) via progressive contrastive→generative alignment.
-
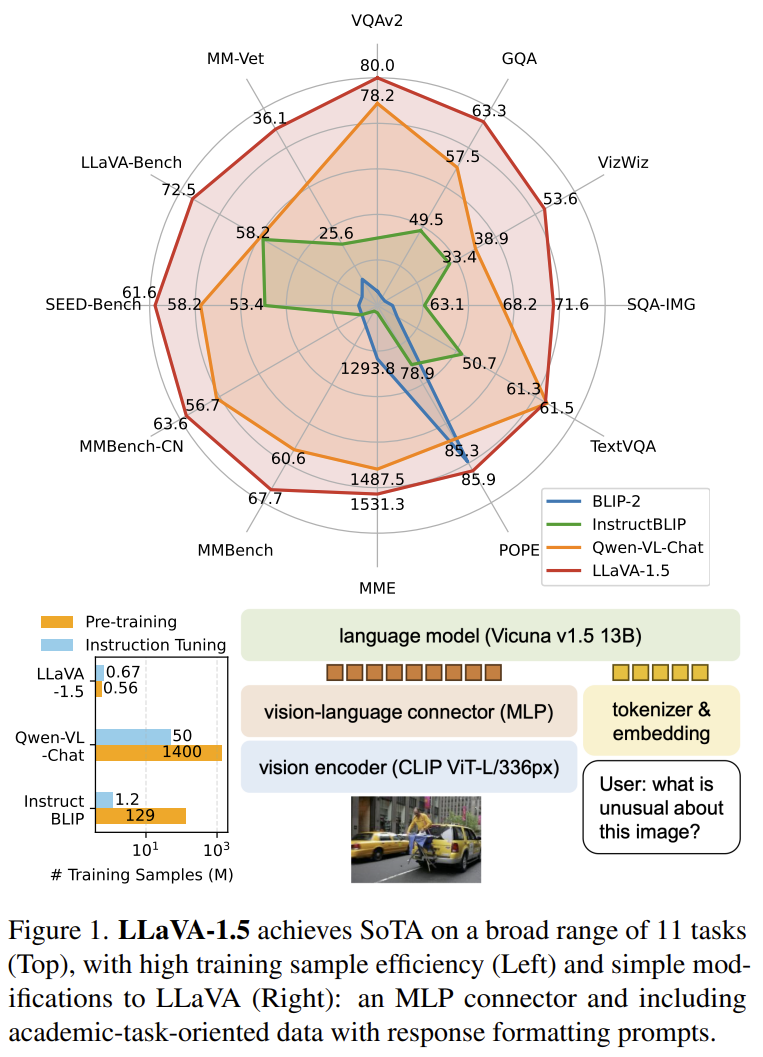
[LLaVA-1.5] Improved Baselines with Visual Instruction Tuning
A systematic study of LLaVA's design choices — an MLP connector, a 336px CLIP encoder, and academic-task VQA data with response-format prompts — sets SOTA on 11 benchmarks with only public data.
-
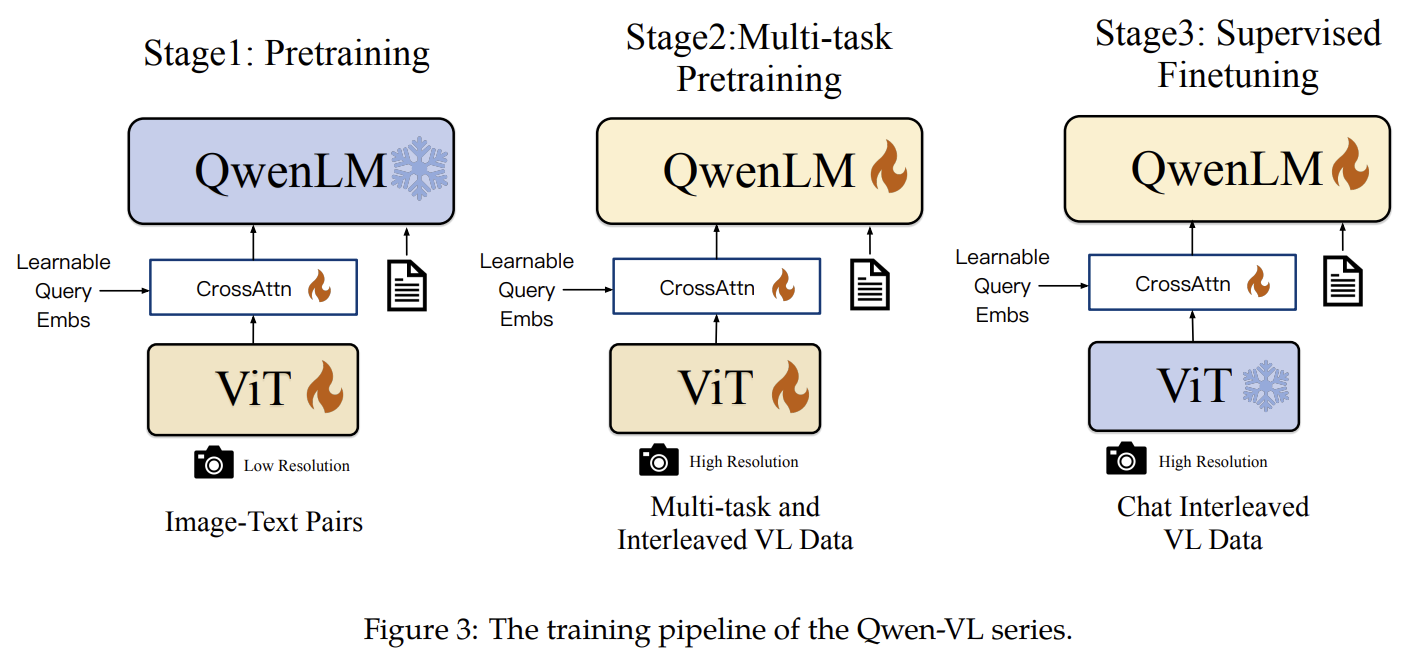
[Qwen-VL] A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Adds vision to Qwen-7B via a ViT + position-aware cross-attention adapter (256 query tokens), trained in 3 stages — and adds grounding and text-reading via box/ref special tokens.
-
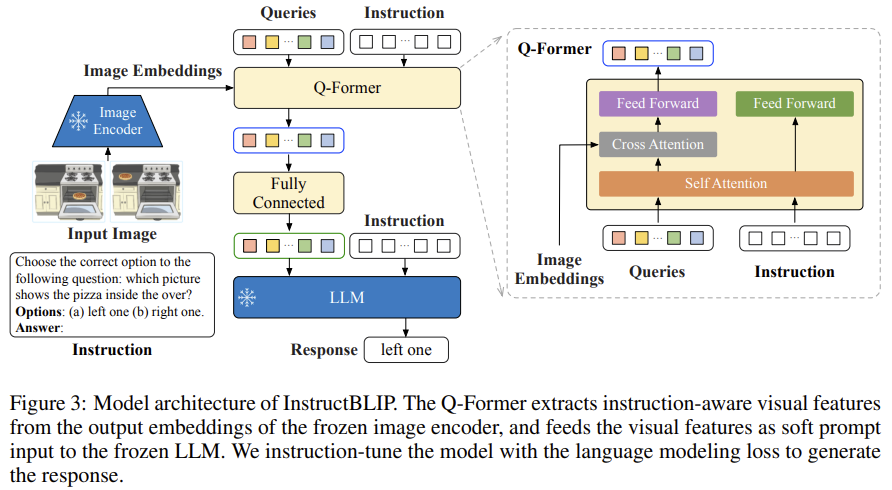
[InstructBLIP] Towards General-purpose Vision-Language Models with Instruction Tuning
Instruction-tunes BLIP-2 on 26 datasets, and makes the Q-Former instruction-aware — feeding the instruction to the Q-Former so it extracts visual features tailored to the task.
-
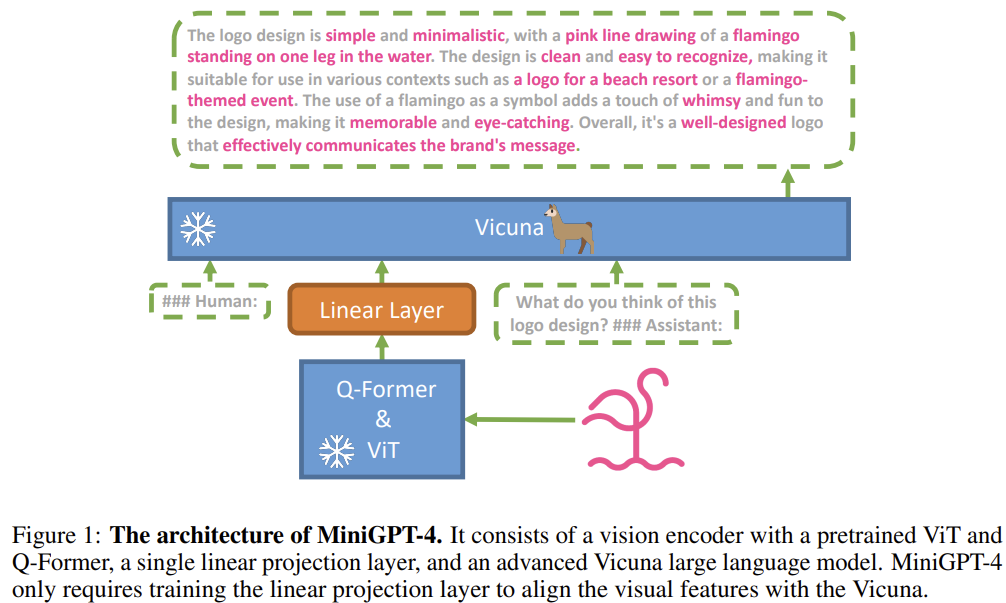
[MiniGPT-4] Enhancing Vision-Language Understanding with Advanced Large Language Models
Aligns a frozen vision encoder (BLIP-2's ViT+Q-Former) and a frozen Vicuna with a single linear projection layer — showing GPT-4-like abilities emerge from minimal alignment of a strong LLM.
-
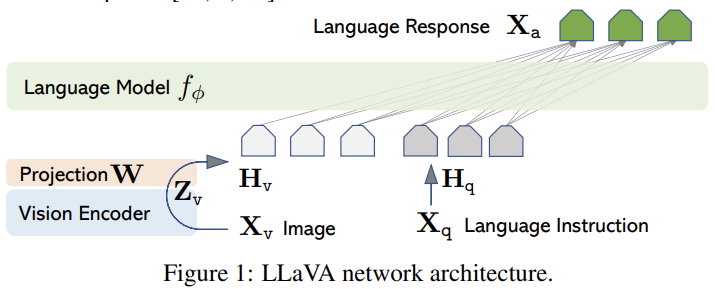
[LLaVA] Visual Instruction Tuning
Uses language-only GPT-4 to generate multimodal instruction-following data, then connects a frozen CLIP encoder to Vicuna with a single linear projection and instruction-tunes end-to-end.
-
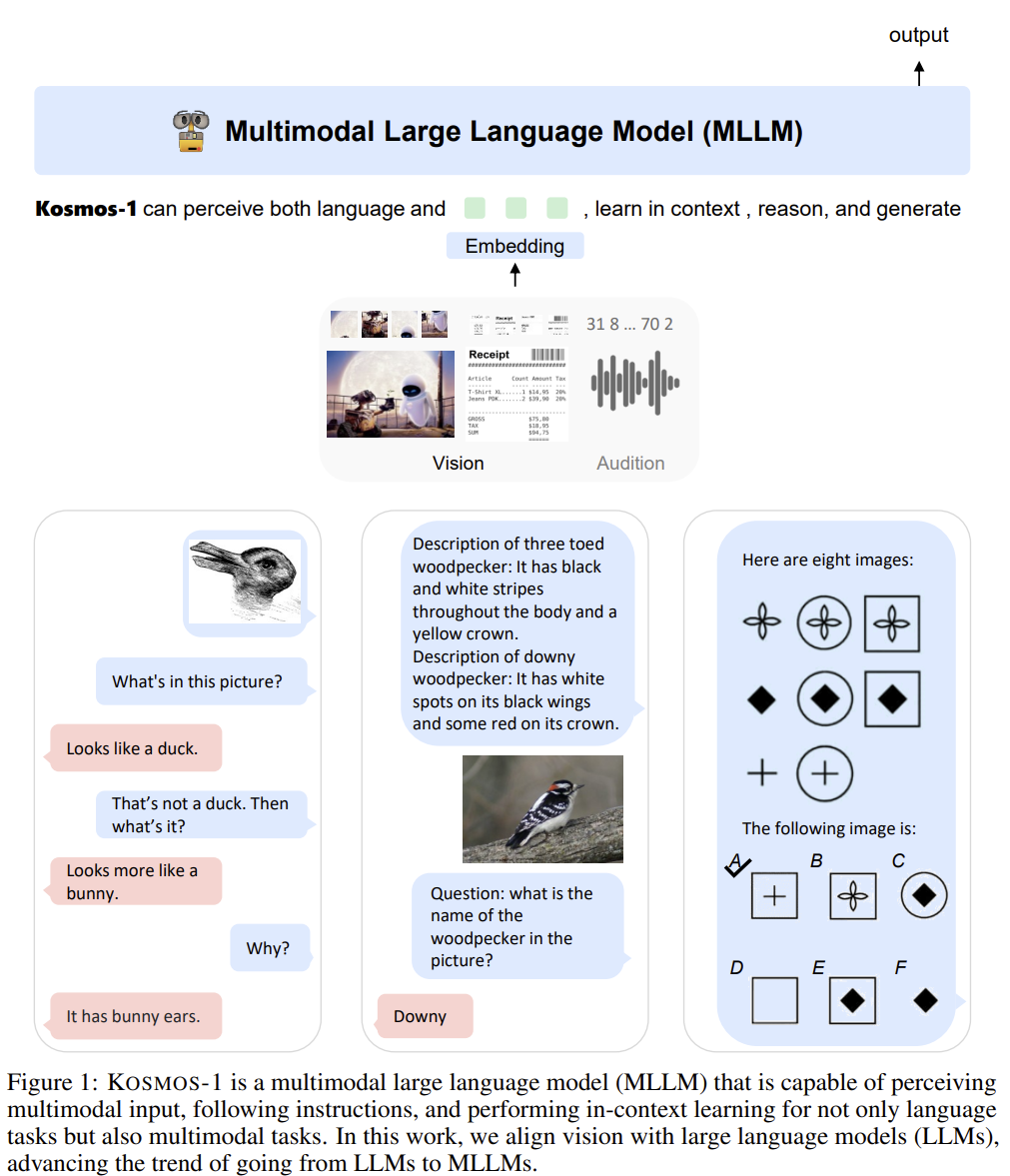
[Kosmos-1] Language Is Not All You Need: Aligning Perception with Language Models
A multimodal LLM trained from scratch on web-scale interleaved image-text — perceiving general modalities, learning in context (few-shot), and following instructions (zero-shot), without a frozen LLM.
-
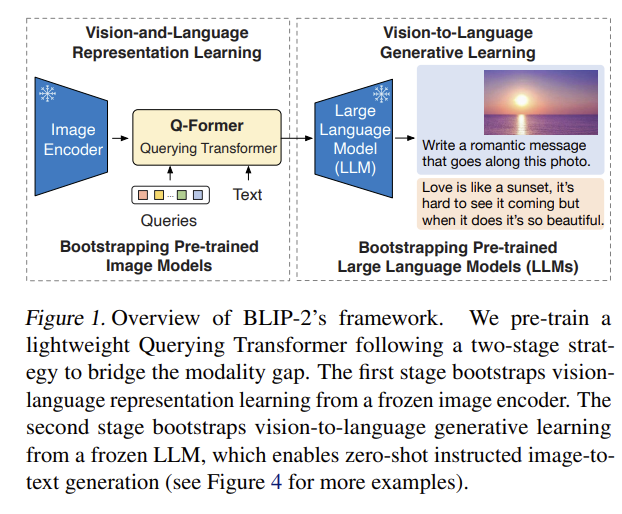
[BLIP-2] Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
Bridges a frozen image encoder and a frozen LLM with a lightweight Querying Transformer (Q-Former), pre-trained in two stages — representation learning then generative learning.
-
[Flamingo] Flamingo: a Visual Language Model for Few-Shot Learning
Bridges a frozen vision encoder and a frozen LLM with a Perceiver Resampler + gated cross-attention, unlocking GPT-3-style few-shot in-context learning on image/video tasks.

-
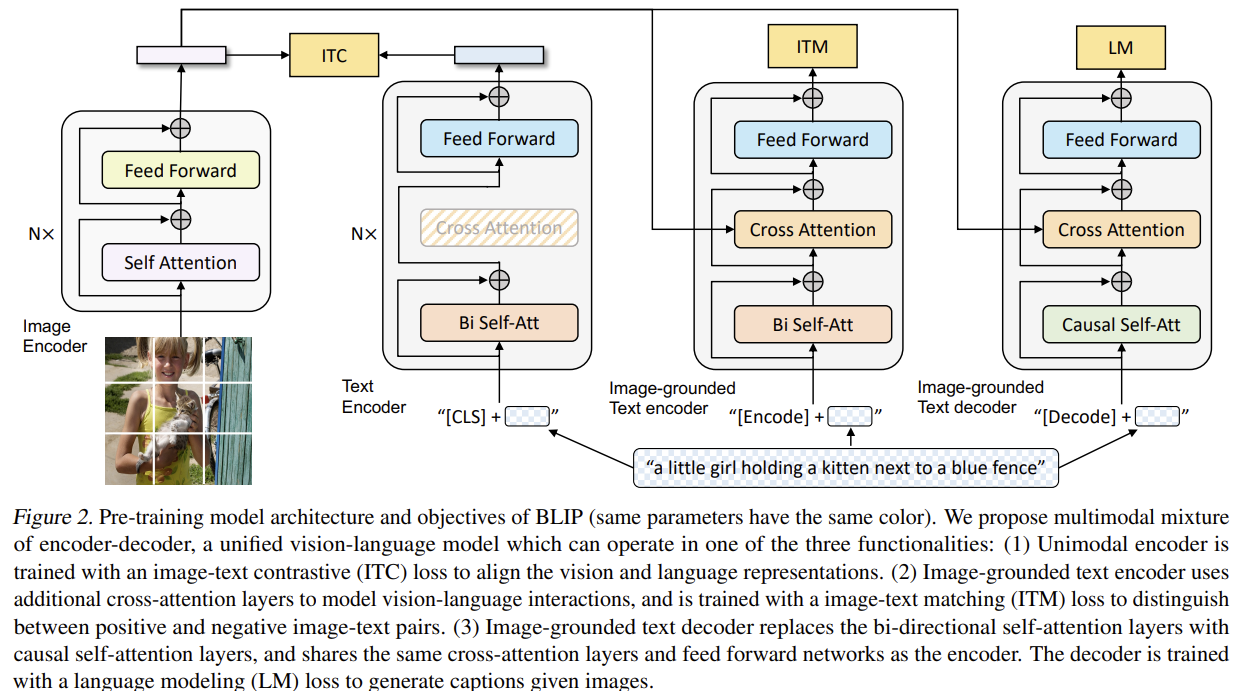
[BLIP] Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
A unified vision-language model (MED) that handles both understanding and generation, plus CapFilt — a captioner+filter that bootstraps noisy web captions into cleaner training data.